Привет, меня зовут Руслан, я руковожу тестированием в Максилекте. Сегодня поговорим о базовых понятиях Devops, которые пригодятся автоматизатору. Расскажу про CI/CD в целом — что это такое и для чего оно нужно, а также про Docker. Объясню на пальцах, как развернуть тестируемый сервис в Docker-контейнере и пробросить к нему порты, как запустить тесты снаружи или внутри контейнера.

Сам я пока еще изучаю детали. Так что воспринимайте статью как своеобразный шеринг знаний. Я рассказываю о том, что попробовал и мне понравилось. Обсуждение конкретных инструментов и того, как автоматизатору со своей частью работы встроиться в процесс сборки, оставим на будущее.
Что такое CI/CD
Это одна из практик devops. Она позволяет разработчикам сосредоточиться на реализации бизнес-требований, качестве кода и безопасности.
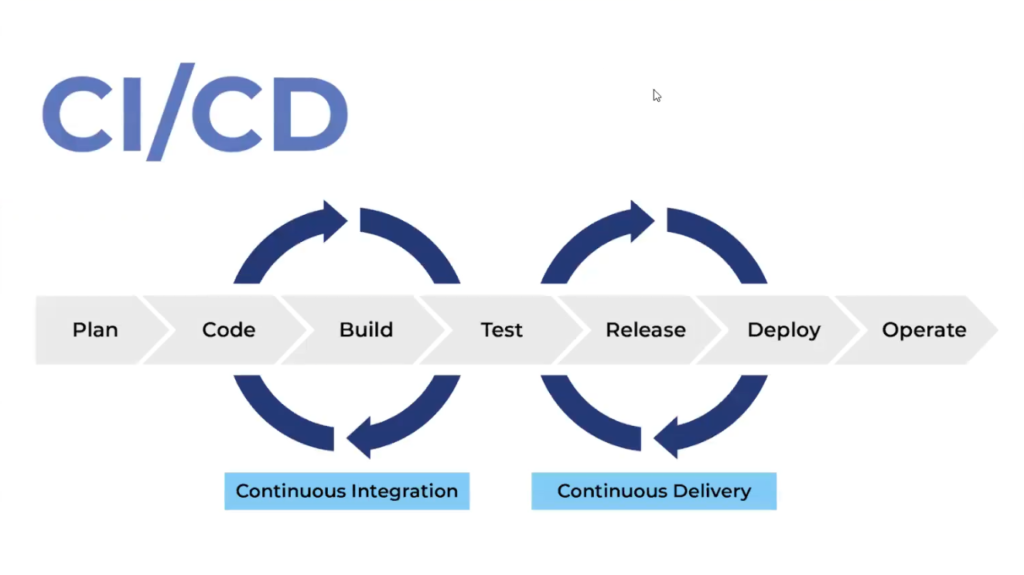
CI/CD — это continuous integration и continuous delivery.
CI — это build-test процесс, в рамках которого приложение собирается и тестируется. На этапе CD мы разворачиваем приложение в разных окружениях (тестовые контура, стейджинг, продакшн).
Непрерывное тестирование в цепочке CI/CD играет одну из ключевых ролей — где-то между CI и CD.
На нашем проекте Android-приложения это выглядит так. Функциональные тесты под один спринт на следующих итерациях становятся регрессионными и показывают, не задели ли очередные изменения в приложении другие его части. Всего в проекте около 700 регрессионных тестов. Если какой-то из них не проходит, сборка фейлится и не деплоится в продакшн. Так мы можем довольно быстро и безболезненно деплоить.
Смоук-тесты запускаются в другой части процесса — в момент создания pull-request разработчиком. В нашем случае Teamcity по hook-ам получает событие (создание pull-request), запускает цепочку сборок и сами тесты. И по результатам тестирования принимается решение об объединении ветки разработчика с релизом. Плюс этой схемы в том, что разработчики могут достаточно часто коммитить изменения, а не накапливать их для детального тестирования.
И все это выполняется автоматически по скриптам. Никаких ручных действий и танцев с бубном. Если на каком-то этапе тесты не проходят, мы даже не деплоим. В итоге сокращается время доставки изменений. Сборка приложения занимает минут 20, еще столько же проходит набор регрессионных тестов в 20-30 потоков. Еще 20 минут требуется на деплой. В итоге мы за час проходим весь процесс от билда до деплоя.
Docker
Важную роль в нашем процессе работы играет Docker.
У нас есть пул “чистых” агентов, на которых ничего не предустановлено (кроме необходимого для работы с Docker). И есть множество проектов на разных стеках. У каждого проекта — свои требования по библиотекам, SDK и т.п. И благодаря Docker бизнес-линии могут не делить поровну агентов между собой, а использовать общие ресурсы в соответствии со своими потребностями. Для этого они берут из хранилища и разворачивают на агентах необходимые Docker-образы (с нужными версиями библиотек). Каждая бизнес-линия использует свои Docker-образы с любыми экзотическими инструментами, если таковые требуются.
Я воспринимаю Docker как контейнер, который может жить где угодно. Я могу поставить контейнер, накидать туда все, что хочу, и перетаскивать его целиком. Что-то оттуда доставать, что-то туда класть.

Поясню, как это происходит, на примере случая с тестовым заданием, которое мы даем ручным тестировщикам. Локально тестовое задание у меня отлично запускалось, но не так давно один из кандидатов пожаловался, что у себя запустить не может. Я сообщил все необходимые версии, но задание все равно не запустилось. Выяснилось, что несмотря на попытки кандидата установить нужную версию Java, использовалась другая. Это распространенная ситуация. Но если бы мы завернули тестовый сервис в некую защищенную оболочку, которая работает почти везде, и отдавали бы кандидатам образы, все было бы проще. За редким исключением кандидату было бы достаточно предустановить Docker. Это в разы сократило бы потраченное время.
Отмечу, что в тестовые задания мы тащить Docker не собираемся — все-таки нам не важно умение разворачивать контейнеры. Хотя в целом и разработка, и тестирование уходят в контейнеры, так что со временем, возможно, мы поменяем свое мнение.
Но вернемся к Docker.
Dockerfile
Файл Dockerfile — это набор инструкций, следуя которым Docker собирает образ контейнера. В частности, он содержит описание основы — базового образа. Среди популярных образов можно отметить:
- Python;
- Ubuntu;
- и т.п.
Поверх базового образа можно добавлять слои. Но чем меньше слоев, тем лучше — быстрее будет работать.
В docker-файле используются разного рода инструкции. Вот список тех, что мы используем в повседневной работе (но это не все инструкции):
- FROM — задает базовый (родительский) образ;
- LABEL — описывает метаданные, например сведения о том, кто создал и поддерживает образ;
- ENV — устанавливает постоянные переменные среды;
- RUN — выполняет команду и создает слой образа; используется для установки пакетов в контейнер. Поскольку чем меньше слоев, тем быстрее все будет работать, мы по возможности объединяем все команды RUN в один слой через перевод строки и обратный слеш;
- COPY — копирует в контейнер папки и файлы;
- ADD — копирует папки и файлы в контейнер, может распаковывать локальные .tar-файлы;
- CMD — описывает команду с аргументами, которую нужно выполнить, когда контейнер будет запущен; аргументы могут быть предопределены при запуске контейнера. В файле может присутствовать лишь одна такая инструкция;
- WORKDIR — задает рабочую директорию для следующей инструкции;
- ARG — задает переменные для передачи Docker во время сборки образа;
- ENTRYPOINT — предоставляет команду с аргументами для вызова во время выполнения контейнера. Аргументы не переопределяются;
- EXPOSE — указывает на необходимость открыть порт;
- VOLUME — создает точку монтирования для работы с постоянным хранилищем.
А еще есть .dockerignore, который помогает игнорировать определенный список файлов и папок при сборке образа. Правда, работает он только с командами ADD и COPY.
Одна из сильных сторон докера — кеширование, благодаря которому ускоряется сборка образов. Если при прочтении очередного docker-файла, в кеше обнаруживается схожая инструкция, в образ добавляется содержимое кэша. Если же попадания в кэш нет, идет сборка этого слоя с нуля. Поэтому если в контейнерах есть динамические вещи, их лучше добавлять в верхние слои docker-образа. Кроме того, следует быть аккуратными с добавлением в образ библиотек, список которых приведен в текстовом файле. Механизм кеширования не заметит, что содержимое текстового файла изменилось. Отмечу, что эффект от кеширования заметен не на всех примерах.
Управление контейнерами и образами
Общая схема команды для управления контейнерами выглядит следующим образом:
docker container my_commandВместо my_command можно подставить:
- create — создание контейнера из образа;
- start — запуск существующего контейнера;
- run — создание контейнера и его запуск;
- ls — вывод списка работающих контейнеров;
- inspect — вывод подробной информации о контейнере;
- logs — вывод логов;
- stop — остановка работающего контейнера с отправкой главному процессу контейнера сигнала SIGTERM (и через некоторое время SIGKILL);
- kill — остановка работающего контейнера с отправкой главному процессу контейнера сигнала SIGKILL;
- rm — удаление остановленного контейнера.
Схема команды для управления образами:
docker image my_command1Вместо my_command1 можно подставить:
- build — сборка образа;
- push — отправка образа в удаленный реестр;
- ls — вывод списка образов;
- history — вывод сведений о слоях образа;
- inspect — вывод подробной информации об образе, в том числе — сведений о слоях;
- rm — удаление образа.
Немного практики
Предположим, у нас есть сервис, который запускается командой:
mvn jetty:runДавайте попробуем добавить его в контейнер, а потом запустить тесты снаружи или внутри контейнера.
Создадим образ
Для начала в корневой папке проекта создадим текстовый docker-файл. Я нашел базовый образ с уже предустановленной java8 и maven. Возьмем его за основу инструкцией FROM и обозначим рабочую директорию:
FROM maven:3.5-jdk-8
WORKDIR /usr/src/rest-clientСкопируем все файлы нашего проекта в контейнер:
COPY . .И запустим команду, которая установит Allure:
RUN apt update && \
mkdir allure && \
cd allure &&wget https://github.com/ allure-framework/allure2/releases/download/2.13.8/allure-2.13.8.zip && \
apt install unzip -y && \
unzip allure-2.13.8.zipЗдесь мы как раз объединили все в одну большую RUN команду, используя символ переноса строки для удобства чтения. Один RUN создает только один слой вместо нескольких.
Мы качаем архив с Allure, распаковываем его (в данном случае в каталоге allure).
Можно сохранять docker-файл и создавать образ:
docker build -t example/rest-client:1.0 Мы не указываем путь к docker-файл, поскольку изначально разместили его в корневом каталоге.
При создании образа ему будет присвоен ID.
Создадим контейнер
При создании контейнера мы указываем путь к образу и пробрасываем порты. Первое число — порт хост-машины, второе — порт внутри контейнера. Здесь же можно выполнить команду — в данном случае я запускаю сервис:
docker run -p 28080:28080 -p 28081:28081 example/rest-client:1.0 mvn jetty:runПри выполнении этой команды некоторое время потребуется на подтягивание разных зависимостей.
Запустим автотесты
Итак, сервис запущен в контейнере. Чтобы запустить автотесты снаружи контейнера, которые в нашем случае присутствуют на локальном порту 28080, необходимо использовать команду:
mvn clean testВ итоге мы получаем результат в allure-results.
Тесты можно запустить и внутри контейнера. Для этого нам надо попасть внутрь при помощи команды, которая открывает bash:
docker exec -it container_ID /bin/bashЗапускаем наши тесты внутри контейнера:
mvn clean testВ рабочей директории rest-client (мы ее обозначили рабочей в dockerfile) есть папка allure. Когда тесты пройдут, внутри появится папка target. Для получения отчета Allure на локальном хосте можно запустить внутри контейнера Allure Report:
./allure serve -р 0.0.0.0 -p 28081 /usr/src/rest-client/target/allure-results/Результаты будут доступны на localhost:28081.
Вот и все.
Мы создали докер-образ, запустили на его основе докер-контейнер, пробросили порты. Мы получили доступ к сервису из контейнера на хост-машину и можем запускать тесты как локально, так и непосредственно в контейнере. Также мы запустили Allure Report на определенном порту и получили доступ к результатам локально.
Удачи с экспериментами!
Автор: Руслан Абдулин, Максилект.