В этой статье обсудим уровни изолированности транзакций и как их можно использовать на своих проектах. Среди прочего эту тему часто поднимают на собеседованиях, поэтому в том или ином виде с ней знакомы многие. Но здесь мы разберем некоторые нюансы.

Всем привет! Меня зовут Валерий, я работаю на собственном проекте Максилекта — Mondiad.
Короткое определение
Уровень изолированности — это условный уровень консистентности данных, который может быть достигнут при выполнении параллельных транзакций. Грубо говоря, это те ограничения, на которые мы готовы пойти, выполняя параллельные запросы в базу, чтобы сохранить целостность данных.
Уровень изолированности — это часть требований ACID (atomicity — атомарность, consistency — согласованность, isolation — изолированность и durability — надежность). Реляционные базы данных в большинстве своём должны удовлетворять этим требованиям. Части этих требований удовлетворяют и некоторые нереляционные базы.
Какие проблемы можно решить
Проблемы, которые решает механизм изолированности, интереснее рассматривать, чем голую теорию.
Выбор подходящего уровня изолированности позволяет справиться с несколькими из них:
- dirty read — с чтением данных, которые могут пропасть после отката;
- non repeatable read — с повторным чтением, которое может вернуть изменившиеся данные;
- phantom read — с повторным чтением, которое может вернуть отличающееся количество строк;
- lost update — с потерянным измением.
Первые три пункта этого списка упоминаются в большинстве источников. Четвертый я обнаружил только в русскоязычной Википедии. Там же есть пример, позволяющий воспроизвести эту проблему. Но мне в тестах на Kotlin повторить ее не удалось.
Все эти пункты далее мы рассмотрим на примерах.
Уровни изолированности, описанные в стандарте
В стандарте SQL от ANSI/ISO, сформулированном еще в 1992 году, описаны четыре уровня:
- Read uncommitted — чтение незафиксированных данных;
- Read committed — чтение зафиксированных данных;
- Repeatable read — повторяющееся чтение;
- Serializable — упорядочиваемость.
Некоторые современные базы данных также реализуют еще один уровень:
- Snapshot (опционально) — снимок состояния (четкого определения я в источниках не нашел, поэтому назвал это просто снимком состояния).
Эти уровни выстроены по степени от наименьшей консистентности к наибольшей. Т.е. чтение незафиксированных данных дает нам наибольшую вероятность прочитать информацию, которая была изменена соседней транзакцией. А serializable фактически выстраивает транзакции в очередь — они выполняются друг за другом.
За то, как уровни изолированности работают в самих базах данных, отвечает их внутренняя реализация. Требования по стандарту к уровням изолированности они соблюдать должны, а вот внутреннюю реализацию копировать не обязаны. Разные разработчики воплощают идеи по-своему, но в целом механизм складывается из lock-ов на чтение и запись. Соответственно, каждый из уровней имеет свой набор этих lock-ов.
Я собрал небольшую таблицу — внес в нее основные БД, с которыми работал ранее (пожалуй, в нашей сфере это наиболее используемые БД):
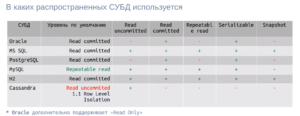
Когда мы заводим транзакцию и не задаем конкретный уровень, БД использует уровень изолированности по умолчанию. Для меня было сюрпризом, что у MySQL изолированность по умолчанию на один порядок выше, чем у того же PostgreSQL или Oracle. Возможно, это связано с подкапотной реализацией этих механизмов (возможно, если по умолчанию использовать в MySQL уровень “чтение зафиксированных данных”, то эта база данных не отдаст нужный уровень консистентности для операций).
Кстати, среди примеров вы также можете увидеть нереляционную базу Cassandra.
Она поддерживает только три пункта из ACID-требований: атомарность, изолированность и надёжность, но не поддерживает консистентность в привычном виде. Она поддерживает так называемую “консистентность в конечном счете”, т.е. в какой-то момент времени она может быть не консистентна, но когда-нибудь точно таковой станет. В этой БД транзакционный уровень изолированности реализован, только начиная с версии 1.1, причем на уровне строки, т.е. операция записи выполнится, зафиксирует состояние, когда завершится транзакция, но соседняя транзакция не увидит изменённые колонки, пока не произойдет коммит. Связано это с механизмом партиционирования. Запись отправляется на несколько партиций, у которых должен произойти кворум.
Еще один интересный момент, который я для себя обнаружил, — некоторые базы данных под капотом либо вообще не заявляют некоторые уровни изолированности, либо поддерживают их за счёт fallback:
- У Oracle на официальном сайте указано, что БД поддерживает только чтение зафиксированных данных и упорядочиваемость. Еще у нее есть такой интересный режим, как Readonly. Сам я, к сожалению, с Oracle работал давно и не на том уровне, на котором хотелось бы. Но как я понял, транзакция Readonly фактически работает на уровне Snapshot, но кроме того совсем не позволяет делать изменения.
- MySQL поддерживает все заявленные в стандарте уровни и дополнительно Snapshot. Реализовано все более-менее честно. Однако чем в данном случае Repeatable read отличается от Snapshot, сказать сложно — формулировка размытая. Мне кажется, суть там в деталях реализации. На базе MySQL я подготовил несколько примеров на Kotlin — в них мне удалось повторить все проблемы, заявленные в начале. И продемонстрировать, что повышение уровня изолированности их решает.
- PostgreSQL интересна тем, что заявляет поддержку всех четырех уровней из стандарта, но реализует их за счет fallback. Запрашивая уровень чтения незафиксированных данных, мы откатимся до более высокого уровня — чтения фиксированных данных.
- H2 я привёл просто до кучи. Это in memory база данных, которая используется в узких кейсах (например, для тестов). У неё заявлены все четыре уровня, определенные стандартом, плюс Snapshot. Из своей практики я знаю, что H2 умеет притворяться БД PostgreSQL.
Перед тем, как перейти к примерам, хочу также сделать одно замечание относительно Spring. Мы, как Java разработчики, активно используем этот фреймворк. У него есть очень удобные механизмы работы с транзакционностью, которые среди прочего позволяют задавать уровни изоляции.
@Transactional(isolation = Isolation.READ_UNCOMMITTED)
@Transactional(isolation = Isolation.READ_COMMITTED)
@Transactional(isolation = Isolation.REPEATABLE_READ)
@Transactional(isolation = Isolation.SERIALIZABLE)
@Transactional или @Transactional(isolation = Isolation.DEFAULT)Причем, мы можем задать все четыре заявленные стандартом уровня, а можем и не задавать его вовсе (указав аннотацию транзакционности без конкретного уровня) — в этом случае будет использован уровень по умолчанию. Фактически, фреймворк отдаст его выбор на сторону БД. В большинстве реляционных БД это будет чтение зафиксированных данных, а у MySQL — повторяемое чтение.
Примеры
Код всех примеров можно найти на GitHub: https://github.com/filius/transaction-isolation.
Пример 1: lost update
В первом примере я попробую воспроизвести проблему потерянных изменений, которая заявлена в русскоязычной Википедии.
Предположим, у нас есть две параллельные транзакции. В идеальном мире они запускаются и выполняются одновременно. В нашем случае они выполняют обновление строки с одинаковым идентификатором и делают инкрементальное увеличение значения в какой-то колонке.
// Transaction 1 | Transaction 2
// UPDATE test_table SET value = value + 20 WHERE id=1; | UPDATE test_table SET value = value + 20 WHERE id=1;К сожалению, у меня так и не получилось воспроизвести ситуацию, когда одна транзакция прочитала value и начала в него писать, а в это же время вторая транзакция прочитала это же value и тоже начала в него писать. При любом уровне изолированности, как бы я не пытался опуститься как можно ниже, у меня не получилось заставить работать эти операции параллельно. Транзакции становятся в очередь скорее всего на уровне БД. Во время UPDATE на строку, для которой выполняется эта операция, ставится lock на запись, поэтому следующая операция, которая пытается захватить этот lock, вынуждена ждать.
В целом по самой операции UPDATE видно, что она должна быть атомарной. Наверное, это правильно, что современные базы данных не позволяют производить такое в параллельном режиме. Хочется надеяться, что мы не получим такой проблемы ни при каком уровне изолированности. Возможно, эта проблема пришла к нам из прошлого и поэтому вне русскоязычной Википедии уже не упоминается.
Однако мне удалось воспроизвести проблему при помощи Hibernate. В Hibernate в рамках одной транзакции мы можем прочитать сущность, изменить ее и отправить на сохранение. В этом случае у нас не будет операции инкремента. Вместо нее мы просто укажем, какое значение хотим применить. И на некоторых уровнях изолированности мы можем это сделать, потому что они позволяют выполнить последнюю из операций обновления, не устанавливая lock на запись.
Чтобы продемонстрировать это, я написал тест:
@Test
fun test() {
val future1 = CompletableFuture.runAsync {
trouble01LostUpdateService.increaseValue(
name = "TX1",
entityId = entityId,
increment = 20
)
}
val future2 = CompletableFuture.runAsync {
trouble01LostUpdateService.increaseValue(
name = "TX2",
entityId = entityId,
increment = 30
)
}
future1.get()
future2.get()
val actual = getEntityById(entityId)
logger.info { "Read entity with value = ${actual.value}" }
assertThat(actual.value).isLessThan(60) // expected 30 or 40, not 60
}
@Test
fun test2() {
val barrier = CyclicBarrier(3)
val future1 = CompletableFuture.runAsync {
trouble01LostUpdateService.increaseUpdateValue(
barrier = barrier,
name = "TX1",
entityId = entityId,
increment = 20
)
}
val future2 = CompletableFuture.runAsync {
trouble01LostUpdateService.increaseUpdateValue(
barrier = barrier,
name = "TX2",
entityId = entityId,
increment = 30
)
}
Thread.sleep(20)
barrier.await()
future1.get()
future2.get()
val actual = getEntityById(entityId)
logger.info { "Read entity with value = ${actual.value}" }
assertThat(actual.value).isEqualTo(60) // UPDATE .. SET avoided lost of data
}
IDEA показывает, что тест падает. Мы видим время выполнения операций вплоть до миллисекунд. С помощью этих меток можно проследить, как выполняются параллельные транзакции.
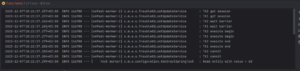
Здесь видно, что у нас есть операции получения сессии, ожидания барьера и начала сессии. До начала сессии оба потока идут параллельно (до миллисекунд). Но после execute begin начинается update — мы берём значение из таблицы, делаем инкремент. И между execute begin и execute end происходит update. Видно, что единовременно выполняется только одна транзакция, а только следом за ней идет вторая. После этого обе транзакции фиксируются.
Таким образом, воспроизвести проблему мне не удалось. Но это было ожидаемо.
Пример 2: dirty read
Предположим, у нас есть транзакция, которая читает значение из базы. Она это делает дважды, а между чтениями другая транзакция выполняет update той же строки. Но в результате вторая транзакция не завершается корректно и происходит откат.
// Transaction 1 | Transaction 2
// SELECT value FROM test_table WHERE id=1; -- (10) |
// | UPDATE test_table SET value=20 WHERE id=1;
// SELECT value FROM test_table WHERE id=1; -- (20) |
// | ROLLBACK;На уровне чтения незафиксированных данных мы можем получить при повторном чтении разные значения — при первом получим 10, а при втором — уже значение обновлённой строки и это будет 20. Однако в результате, когда обе эти транзакции завершатся и значение откатится, в таблице будет 10 (20 было незафиксированным значением).
Отмечу, что данная проблема воспроизводится только на уровне чтения не зафиксированных данных.
@Transactional(isolation = Isolation.READ_UNCOMMITTED)
fun dirtyReadTransaction(entityId: Long) : Pair<Long, Long> {
val entity1 = findEntityById(entityId)
logger.info { "TX1 First read entity with value = ${entity1.value}" }
detach(entity1)
Thread.sleep(1000)
val entity2 = findEntityById(entityId)
logger.info { "TX1 Second read entity with value = ${entity2.value}" }
return Pair(entity1.value, entity2.value)
}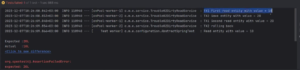
Как видно, тест упал — это его ожидаемое поведение. Первая транзакция отработала и вычитала значение 10, вторая транзакция сохранила значение 20 и второе чтение в первой транзакции вернуло 20. Вторая транзакция откатилась, в результате мы получили, что после выполнения обеих транзакций в базе осталось значение 10.
Если провести эксперимент и поднять уровень изолированности до чтения зафиксированных данных, то тест отработает корректно. Более высокий уровень изолированности установит lock на чтение. Первая транзакция прочитает значение 10. Потом вторая изменит его на 20, но при новом уровне изолированности на этапе второго чтения первой транзакцией это изменение у нас не отобразится. Мы сможем вычитать только зафиксированное значение — 10. Далее транзакция откатится и в базе останется то же значение.
Это верно и для всех последующих примеров — повышение уровня изолированности на один шаг обеспечит прохождение тестов. А вот дальнейшее повышение уровня изолированности уже не изменит результата. Так в этом примере на уровне последовательного чтения тест так же будет зеленым.
Пример 3: non repeatable read
Предположим, у нас опять есть две транзакции. Первая — читает значение. Затем вторая обновляет его и выполняет коммит, после чего первая повторно читает это же значение.
// Transaction 1 | Transaction 2
// SELECT value FROM test_table WHERE id=1; -- (10) |
// | UPDATE test_table SET value=20 WHERE id=1;
// | COMMIT;
// SELECT value FROM test_table WHERE id=1; -- (20) |На уровне чтения зафиксированных данных мы можем получить два разных значения в рамках одной транзакции (это вполне ожидаемое поведение, устанавливая такой уровень изолированности, мы соглашаемся, что этой степени консистентности нам достаточно).
Как выглядит запуск теста:
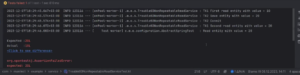
Первая транзакция в первом чтении получила значение 10. Вторая транзакция записала значение 20 и выполнила коммит. Второе чтение первой транзакции вернуло значение 20 — это соответствует ожидаемому уровню изолированности. В результате в БД оказалось значение 20, что также корректно.
В некоторых случаях такое поведение нас может не устраивать — допустим, если нам необходимо получить одинаковые значения в рамках одной транзакции при каждом чтении из базы.
При написании этого теста мне пришлось применить хитрость. Hibernate создает persistence context, в котором сохраняет вычитанные ранее сущности. Из-за этого проблема может не воспроизводиться, поскольку при втором и последующих чтениях значения будут взяты из кэша. Чтобы заставить Hibernate все-таки вычитать значение еще раз, первую сущность (полученную при первом чтении) пришлось открепить от persistence context. Если в этой сущности произвести какие-то изменения, Hibernate уже не будет пытаться их зафиксировать при выполнении коммита в рамках транзакции. После этой манипуляции второе чтение потребовало прямой запрос в БД и вернуло то, что и подразумевалось на уровне чтения зафиксированных данных.
Пример 4: phantom read
Снова рассматриваем две транзакции. В одной мы считываем все строки, которые есть в табличке. По умолчанию при инициализации этой таблицы в ней существует только одна строка идентификатором 1. Вторая транзакция параллельно с первой делает вставку новой записи в эту таблицу и выполняет коммит. В результате в таблице оказывается уже две строки.
// Transaction 1 | Transaction 2
// SELECT value FROM test_table WHERE id>0; -- (10) |
// | INSERT INTO test_table VALUES (2, 20);
// | COMMIT;
// SELECT value FROM test_table WHERE id>0; |
//-- (10) !! doesn't occurred |
// UPDATE test_table SET value 30 WHERE id=2; |
// SELECT value FROM test_table WHERE id>1; |
//-- (10, 30) !! occurred |На уровне повторяемого чтения можно ожидать, что мы получим строку, которая была добавлена второй транзакцией, хотя при первом чтении ее не было. Эта проблема очень похожа на предыдущий пример. Только там мы получали неверное значение в одной и той же записи, а здесь мы можем получить новые или не досчитаться старых записей (при удалении записей проблема также должна воспроизводиться). Это критично, когда мы, например, создаем отчеты и подсчёт некоторых сумм происходит в несколько операций, между которыми возможны новые транзакции.
Чтобы воспроизвести эту проблему в MySQL, мне пришлось в первой транзакции произвести действие над той строкой, которая была вставлена второй транзакцией. Только после этого при чтении удалось вернуть обе записи.
Понимаю, что пример получился довольно синтетический, но в движке MySQL под этот случай реализована отдельная логика — Consistent Nonlocking Read (https://dev.mysql.com/doc/refman/8.0/en/innodb-consistent-read.html).
Согласно пояснению, там используется механизм снапшотов. Когда мы начинаем первую операцию чтения при уровне repeatable read, MySQL делает снимок тех записей, которые мы прочитали. Последующее чтение обращается не в исходный блок данных, а в снапшот. Чтобы сбросить этот снапшот, приходится выполнять операцию update. После этого на повторном чтении в рамках первой транзакции идет обращение к исходному блоку данных.
Запускаем тест — он ожидаемо падает.
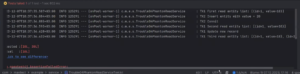
Первая транзакция читает одну строку, вторая транзакция делает вставку и коммит. Первая транзакция во втором чтении всё ещё читает строку, выполняет изменение новой строки, делает третье чтение и получает две записи.
Как говорил выше, если поднять уровень изолированности, тест пройдет. В этом случае транзакции просто встанут в очередь. Хотя если посмотреть на запускаемый код, он никак не меняется — очередь реализуется на уровне базы и та становится однопоточной.
В итоге уровень изолированности — довольно интересный инструмент для оптимизации скорости выполнения параллельных запросов. Но надо быть аккуратным при его понижении, поскольку так мы можем получить неконсистентность данных. И отладка ошибок такого рода довольно проблематична.
А вот повышение уровня изолированности на мой взгляд почти всегда необоснованно, поскольку нивелирует работу, которую мы делаем для распараллеливания кода. Постепенно повышая уровень, мы просто получаем последовательное выполнение.
Автор статьи: Валерий Филатов, Максилект (текст написан по материалам внутреннего митапа)