Kotlin создавался, чтобы избежать некоторых проблем Java. Но как и в любом языке, есть в нем свои особенности. Разрабатывая собственный проект, мы наткнулись на несколько таких моментов. Часть стреляет вам в колено на продакшене, только если вы ими злоупотребляете. Другая отражается на производительности высоконагруженных систем. Все эти моменты сложно заметить, поскольку их не подсвечивают специально плагины для IDE, да и в целом на первый взгляд код похож на валидный.
В этой статье мы поговорим о том, на что нужно обратить внимание.

Не злоупотребляйте обходом null-безопасности
В Kotlin предусмотрены механизмы, которые защищают разработчика от стандартного для Java NullPointerException — так называемая null безопасность. Система типов Kotlin различает те, что могут принимать null-значение (nullable), и те, что null быть не могут никогда. Но встроенную защиту иногда необходимо обойти, и вот тут начинаются неожиданности.
Lateinit
Используя в коде переменную non-null типа, мы должны сразу присвоить ей значение, иначе код не скомпилируется. Но бывают ситуации, когда инициализировать изменяемую non-null переменную нужно не сразу. Например, с таким можно столкнуться в Spring.
Как раз на такой случай в Kotlin предусмотрен модификатор lateinit. Он откладывает инициализацию переменной на потом.
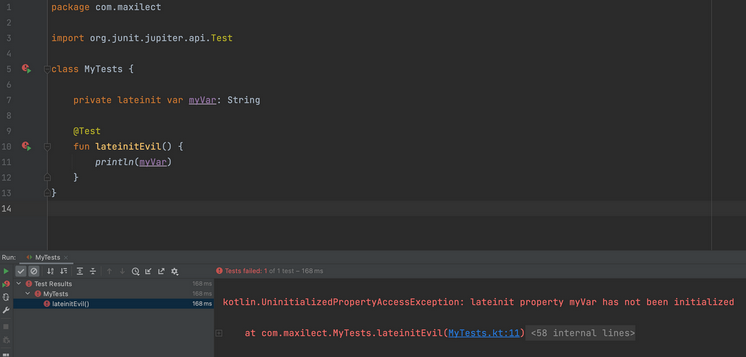
Фактически, подписывая lateinit, мы говорим компилятору, что позаботимся об этом позже (и не будем здесь и сейчас писать лишние проверки на null). Кстати, здесь и далее мы приводим код скриншотами, чтобы было видно, как IDEA подсвечивает синтаксис.
Lateinit — это как валидный костыль от создателей Kotlin. Без него не обойтись. Но когда проинициализировать переменную разработчик все-таки забывает или обращается к ней до того, как инициализирует, уже на продакшене вываливается исключение UninitializedPropertyAccessException. Поэтому злоупотреблять lateinit — ставить его везде, где нет “?” в типе — нельзя. Такую ошибку компилятор не увидит. Проявится она позже.
Кстати, lateinit в принципе нельзя использовать с примитивными типами (подробные разъяснения можно найти здесь).
Оператор !!
Еще один способ объяснить компилятору, кто тут главный — оператор !!.
Если переменная относится к nullable типу, Kotlin не даст с ней работать без предварительной проверки на null. Код, опять же, не скомпилируется. Оператор !! позволяет обойти это ограничение, если разработчик считает, что проверка излишняя (если переменная по логике не должна становиться null, несмотря на тип).
Однако если переменная все-таки окажется null, NullPointerException не избежать, правда, уже не на этапе компиляции, а в рантайме.
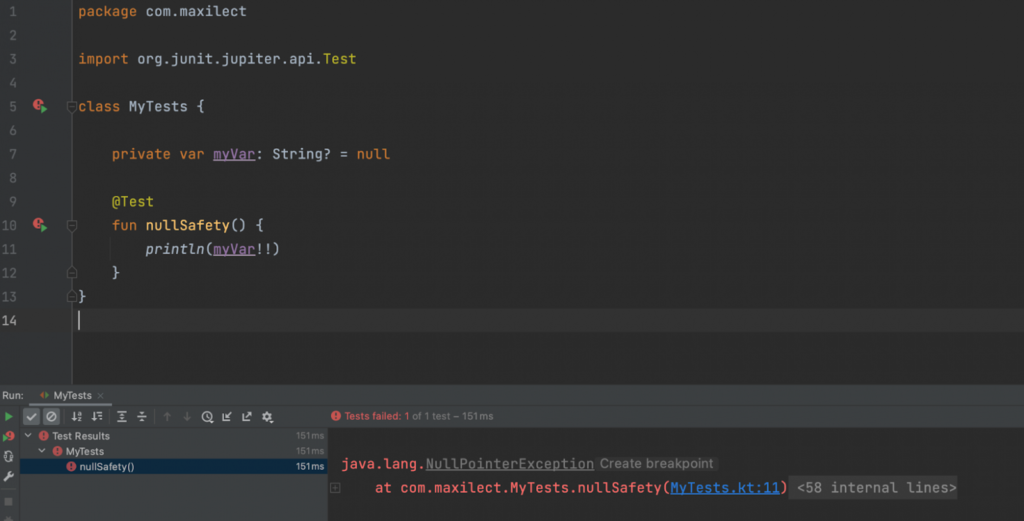
Как и в случае с lateinit, в этой особенности языка нет ничего плохого. Без оператора !! не обойтись. Но и злоупотреблять не стоит.
Аккуратнее с функциями расширения
Перейдем к особенностям языка, которые мы обнаружили при профилировании нашего высоконагруженного сервиса.
В отличие от Java Kotlin умеет расширять классы через extension-функции. Поскольку эти функции связаны с конкретным классом, поведение может меняться как раз в зависимости от используемого класса. И за этим сложно уследить.
Вот пример практически с нашего проекта (код написан специально для статьи, но логика проблемы — из реальной жизни).
Предположим, мы создаем MutableMap, инициализируем ее через ConcurrentHashMap и вызываем getOrPut:
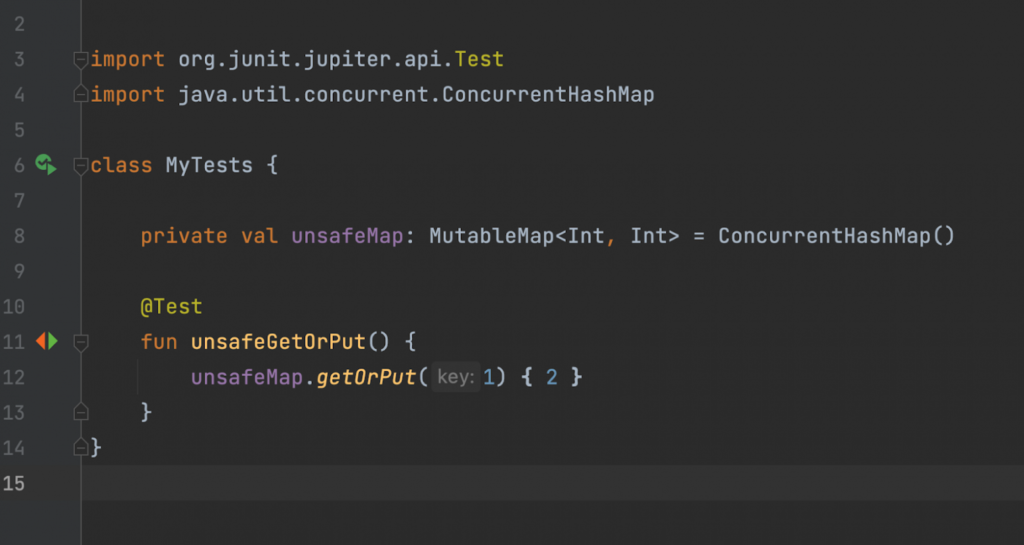
Код выглядит нормально, но работать он не будет.
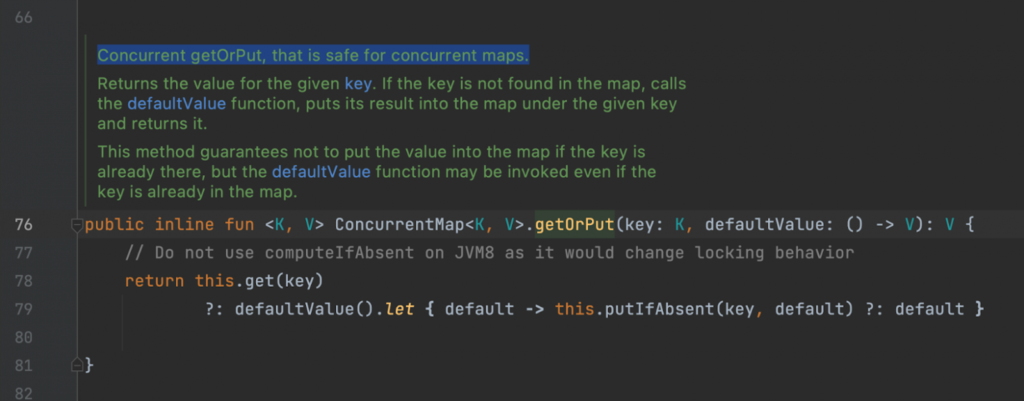
Проблема в том, что getOrPut не относится к методам MutableMap, а значит ConcurrentHashMap не будет его переопределять. getOrPut — это extension-функция MutableMap, которая ко всему прочему еще и не потокобезопасна.
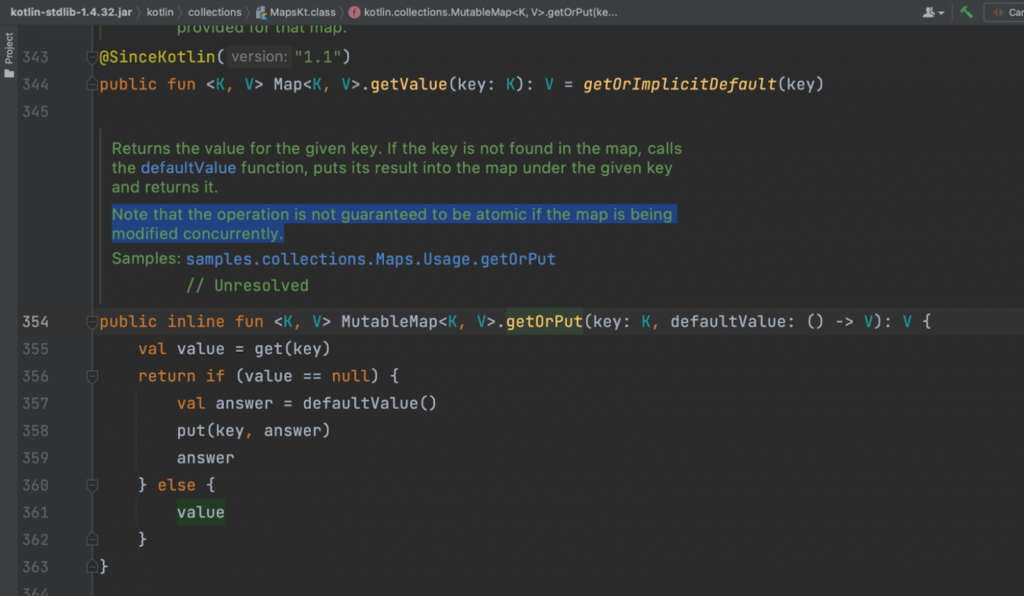
Посмотрим, что под капотом…
Чтобы код заработал, необходимо прописать явно ConcurrentHashMap:
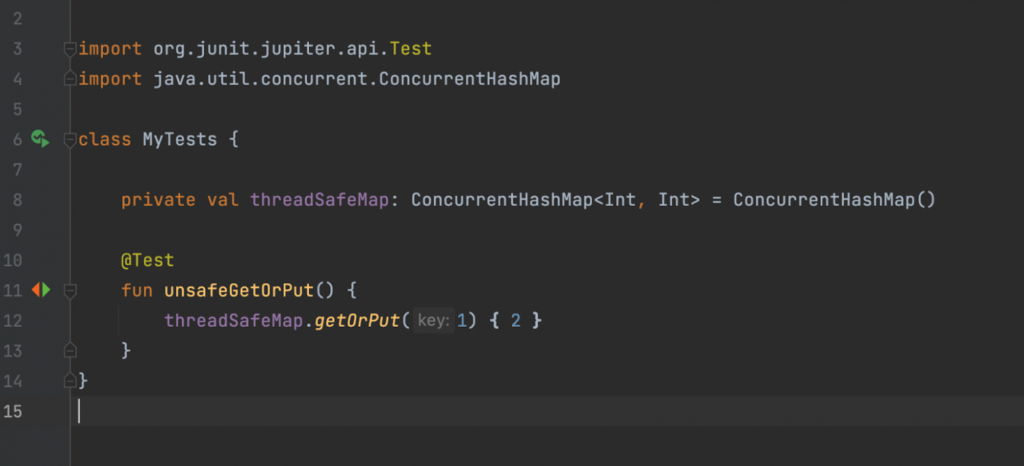
Тогда будет использоваться потокобезопасная extension-функция, т.е. все будет работать корректно.
А вот еще одна похожая ситуация, тоже по мотивам одного из модулей нашего проекта.
В коде мы проверяем наличие “3” и “8” во множестве строк hashSet.
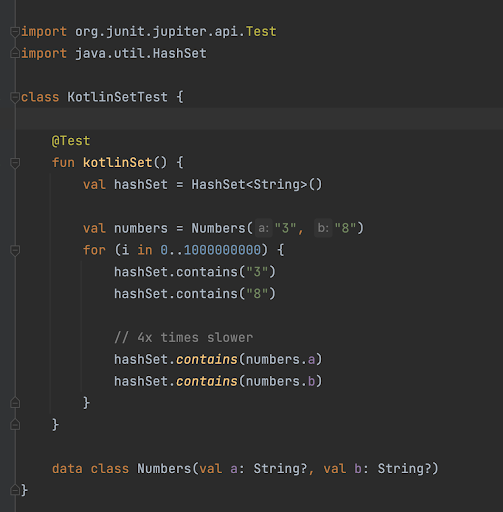
HashSet — класс из Java, который мы используем в Kotlin. Известно, что contains вызывает метод поиска элемента getNode и возвращает true или false очень быстро, вне зависимости от количества элементов в множестве (сложность алгоритма в данном случае — О(1)).
На скриншоте два варианта кода, реализующего нужный нам функционал. В первом случае мы хардкодим строки, которые ищем во множестве. Во втором (после комментария) передаем в метод contains поля переменной numbers.
Практика показывает, что второй вариант в 4 раза медленнее, поскольку вызывает extension-функцию, которая работает по-другому. А все потому, что переменные в дата-классе Numbers имеют другой тип — “String?” (т.е. они nullable). С точки зрения Kotlin мы передаем в contains объект другого типа, поэтому и сам поиск осуществляется иначе — сложность алгоритма возрастает, а скорость падает. И то, что выполнение замедлилось всего в 4 раза, — это наша удача, поскольку hashSet был небольшим.
В обычной системе это никто бы и не заметил. Но в нашем случае только лишь это исправление помогло увеличить производительность на 10% (сервис и до этого работал быстро — мы успели вычистить другие очевидные моменты).
Кстати, починить это можно было оператором !!, хотя мы на проекте в итоге действовали иначе.
Все это не значит, что нужно отказываться от extension-функций, но стоит внимательно смотреть на то, что происходит внутри. Не зря IDEA подсвечивает extension-функции цветом.
Завершая тему extension-функций, хотим поделиться еще одним забавным примером.
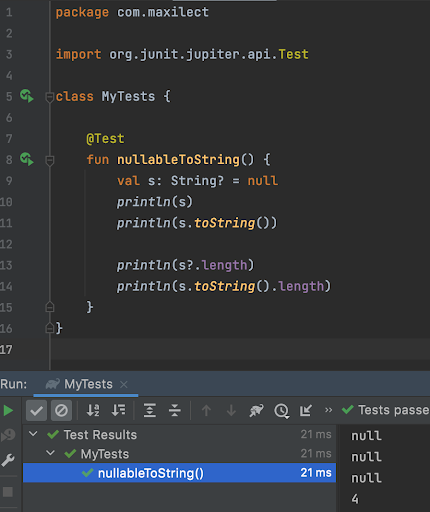
Как мы выяснили на практике, toString() для null-объекта может подкинуть неожиданный результат — “null” в буквальном смысле.
Ищите StringBuilder даже там, где его нет
Для построения строк в Kotlin используется специальный класс StringBuilder (он пришел еще из Java). В ряде ситуаций он помогает быстрее строить строки, не создавая множество промежуточных новых объектов. Но иногда StringBuilder влезает там, где не просят. Вот еще один пример с нашего реального проекта (как и в прошлых примерах, код мы переписали специально под статью).
На первый взгляд на скриншоте безобидный метод:
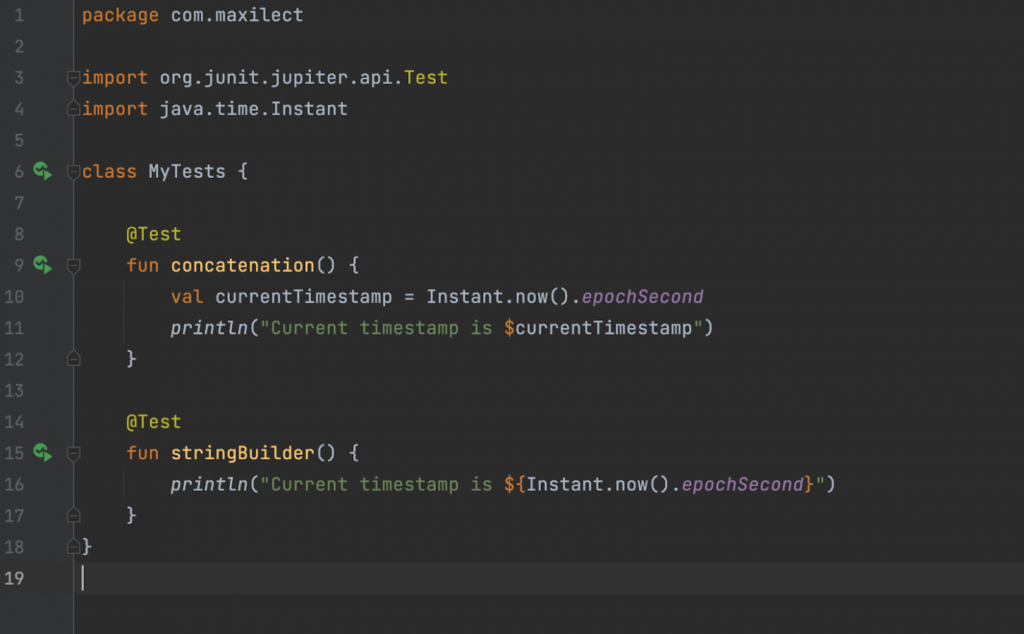
Кажется, что Kotlin складывает две строки через конкатенацию, но на самом деле во многих случаях Kotlin использует StringBuilder. И он тормозит работу, если речь идет о высоконагруженном сервисе.
Kotlin инициализирует StringBuilder с capacity, определяемым некой константой. Если этой capacity не хватает, начинается выделение памяти. И в нашем случае метод выделения новой памяти как раз и тормозил весь сервис. При этом в коде в явном виде StringBuilder-а не было.
На втором скриншоте показан тот же код, но декомпилированный на Java.
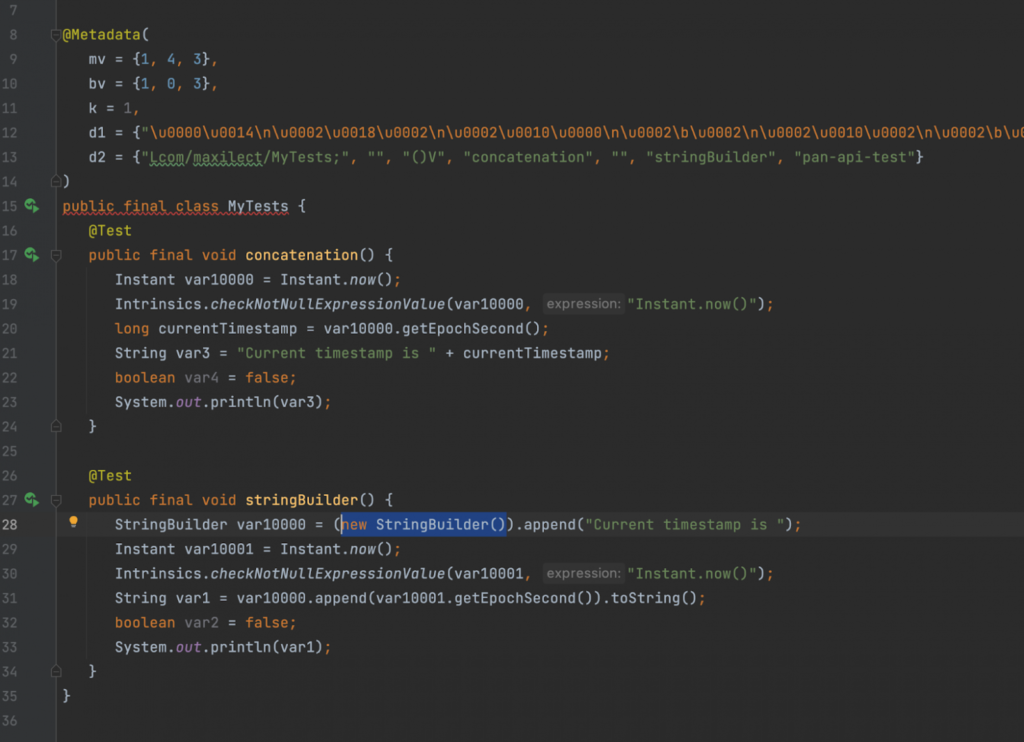
Здесь выделено место, где создаётся новый StringBuilder с capacity по умолчанию 16 символов. Поскольку строка «Current timestamp is» не влезает в эти 16 символов, память выделяется повторно. Получается двойная работа, которая хорошо видна под нагрузкой.
Начиная с Kotlin 1.4.20 заработала конкатенация строк через invokedynamic. Подробнее почитать о том, что это можно по ссылке. Но на нашем проекте мы ее не пробовали — проблему исправили иначе.
Проверяйте дважды после обновления версии языка
В dev, stage и test средах мы используем самый низкий уровень логирования — trace.
Но на продакшене мы отключаем логгер, чтобы производительность не деградировала и жесткий диск не переполнялся (в trace сервис пишет сотни Гб в сутки). Для этого мы по сути добавляли класс, как тот, что выделен на скриншоте, в черный список логирования.
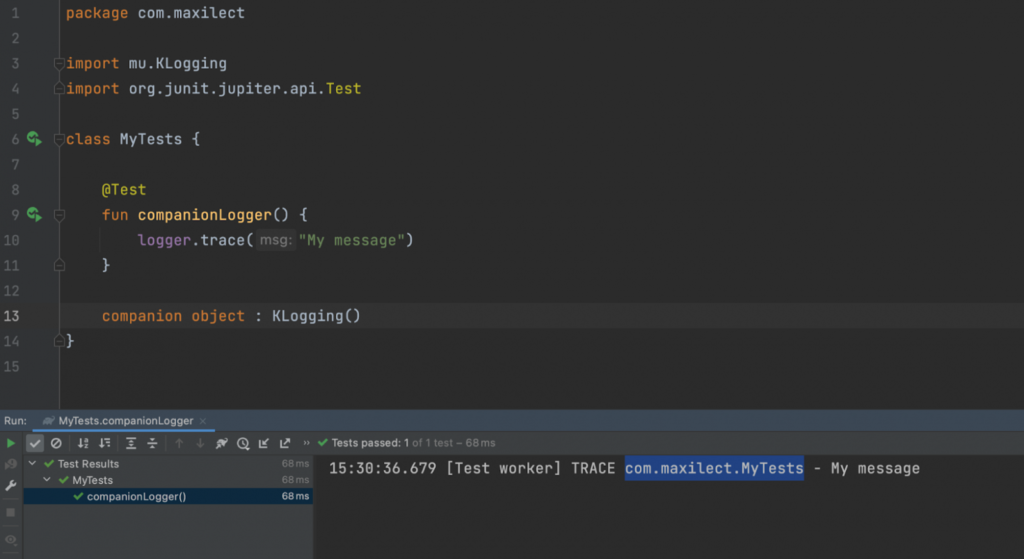
На продакшене логгер у нас был объявлен иначе — через private:
private companion object : KLogging()
Как мы тогда думали, это ни на что не влияет, поскольку используется логгер только внутри класса.
Первое время все действительно работало, как надо. Но потом мы обновили Kotlin и случайно заметили, что вывод логгера изменился. В конец названия класса он добавил $Companion, тем самым вывалившись из черного списка (т.е. “включившись” на проде).
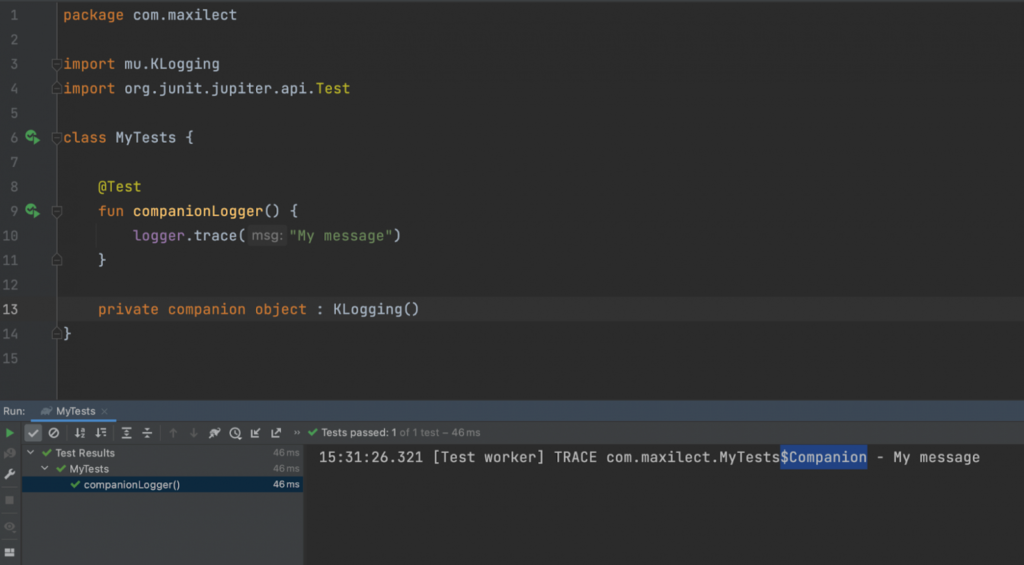
Фактически, мы были в шаге от аварии.
И до сих пор в Kotlin модификатор доступа private влияет на то, как класс называется в логе.
Мы уверены, что наткнулись далеко не на все особенности языка. Самое интересное еще впереди! А приходилось ли вам сталкиваться с чем-то подобным?