Несколько лет назад произошел Kafka-хайп. Kafka хотели использовать все, не всегда понимая, для чего конкретно она им нужна. И сегодня многие продолжают брать Kafka в свои проекты, зачастую ожидая, что её применение само по себе сделает всё лучше.
С одной стороны, это может быть и хорошо. Такие шаги стимулируют индустрию. Но всё же лучше понимать, что ты делаешь, иначе проекту можно сделать только хуже. В этой статье я обращаюсь к разработчикам, аналитикам и тестировщикам, которые еще не сталкивались с Kafka по работе. Помогу понять, почему все же в микросервисной среде многие не ходят просто по REST, а используют этот инструмент — что конкретно делает Kafka и когда есть смысл её применять.
Проблема двух генералов
Эта модель отлично описывает, от чего идет вся боль микросервисов, т.е. отчасти имеет отношение и к Kafka. С нее и начнем.
Об этой концепции много рассказывают, но не так давно я читал статью, в которой автор, кажется, не подозревал, что существует такой закон вселенной и пытался придумать решение, которого нет. Так что начну с азов.
Предположим, у нас на поле есть два генерала, у каждого — своя армия. Между ними враг. Генералы хотят напасть на него с двух сторон. Но нужно договориться, в какое время атаковать и сделать это одновременно, потому что иначе их просто перебьют по одному.

У каждого генерала есть свои гонцы. Первый генерал шлет гонца ко второму, чтобы сообщить — атака начинается завтра в 8 утра. Но враг не дремлет. Он может перехватить гонца, пока тот еще не доехал до второго генерала.
Если гонец добрался без происшествий, второй генерал получил сообщение. Но ему нужно послать гонца с ответом, что информация принята, атака состоится. Первый генерал ведь в курсе обстановки и вряд ли начнет атаку без этого подтверждения. Однако, как и в первом случае, враг может перехватить гонца и тогда первый так и не узнает, что его информация была получена.
Гонец может доехать до первого генерала. Но чтобы атака состоялась, ему нужно опять отправить подтверждение (второй генерал ведь не хочет лезть в пекло один). Получается, что гонцу надо сбегать не просто туда-обратно, но и снова бежать туда, чтобы все убедились в доставке своих сообщений.
Ссылка на подробное описание проблемы.
Выхода из этой ситуации нет — ограничение объективно никак не обойти. Если гонец не вернулся, нам остается только посылать следующего, а потом и следующего, пока кто-то из них не вернется и не подтвердит, что все готовы к атаке.
В микросервисах все происходит точно так же, только роль генералов выполняют эти самые микросервисы, а между ними враждебная сеть — Интернет или локалка, что угодно.
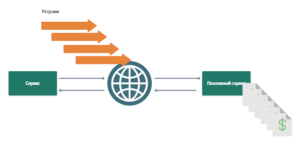
Допустим, нам надо списать 100 рублей с карты некоего Васи с помощью платежного сервиса. Из своего приложения мы обращаемся к нему по REST. Мы можем быть уверены в результате, только если пришли все подтверждения (есть ответы). Ответ может быть “да, деньги списаны” или “нет, не списаны, потому что денег нет”. И это хороший сценарий.

А еще возможна масса ситуаций, когда ответа нет.
Во-первых, мы можем не достучаться нашим запросом до платежного сервиса (сбои в сети или сервис с той стороны недоступен). Платежный сервис мог получить наше сообщение, но не списать деньги, поскольку упал во время обработки транзакции.

Сервис мог списать с клиента деньги, но не ответить нам из-за сбоев в сети или из-за того, что наше собственное приложение лежит, т.е. списание произошло, а обработать это некому.

А еще наше собственное приложение могло упасть уже после того, как списание выполнено, но до того, как сделана пометка об этом.

В двух последних ситуациях деньги мы как бы списали, но на стороне нашего приложения об этом не знаем — т.е. результата все равно нет. В общем случае эта ситуация неразрешима. Как и с двумя генералами, мы можем быть уверены в результате, только если явно получили ответ, что все окей.
Сложный путь от простого REST
При всех неудачных сценариях нам остается дергать платежный сервис и выяснять, что произошло. Но ретраи по REST — тоже не самое удачное решение. Типичный кейс — сеть моргала, а потом оказалось, что мы сделали 10 списаний.
Этот кейс можно лечить с помощью идемпотентности, т.е. на стороне платёжного сервиса мы придумываем механизм, который не позволяет одним и тем же запросом списать деньги дважды. Например, мы можем вводить ID запроса внутрь сообщения и если он повторяется, просто игнорировать этот запрос. И в данном случае именно сервер для данного сообщения должен уметь жить с дупликациями.
Следующая проблема — производительность. Допустим, платежный сервис лег, а мы продолжаем ретраить. Под это нужно будет постоянно держать поток. По сути мы будем DDoS-ить сеть такими ретраями.
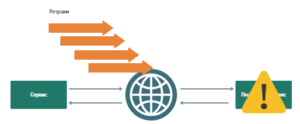
Остается только продумать дополнительные техники — например, если первые ретраи не сработали, повторять запрос через 30 секунд, потом через 2 минуты, потом через 10… Такое удлинение интервала запроса называется backoff. Быть может и вообще стоит остановить ретраи на некоторое время, пока сервис недоступен (это circuit breaker). Можно просто пинать его раз в час, выясняя, не поднялся ли сервис, и возобновить попытки списания только после того, как платежный сервис оживет.
Следующая проблема — это thread starvation. Пока запросы, которые мы ретраим, висят в памяти, треды заняты. Если параллельно к этому же сервису приходят и подвисают новые запросы, рано или поздно треды закончатся. Как результат — OOM, т.е. уже наш сервис перестанет отвечать по этой причине.
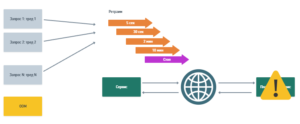
Если в этот момент наш сервис падает, а потом поднимается, то никто уже не вспомнит, что было во всех этих подвисших тредах. Понятно, что обрабатывали какие-то запросы, но какие… Иными словами, мы теряем весь контекст. Продолжить работу мы не можем, нужно все начинать сначала.
Чтобы справиться с этой проблемой, логично не держать треды, а организовать что-то типа очереди, т.е. ретраить уже из промежуточной базы. Удобно сделать фоновый тред, который и будет ретраить эти сообщения.
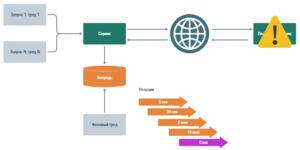
Так мы проходим с REST-ами долгий путь от простого вызова к интересной системе, которая доставляет сообщения хотя бы один раз (можно более одного, ничего страшного) и при этом является eventually consistent, т.е. не консистентной сейчас, но все же консистентной когда-нибудь потом.
А дальше встает вопрос балансировки нагрузки. Если платежный сервис упал, а потом поднялся, все, кто ранее хотели к нему достучаться, начнут заваливать его запросами, которые висят в очереди. Но, быть может, он пока что способен обрабатывать только один запрос в секунду. Т.е. нам нужно работать потише, сбалансировав нагрузку, иначе платежному сервису придется просто откидывать часть запросов лимиттером.
Где-то на этом этапе и возникает идея, что раз у нас уже есть какая-то персистентная очередь, почему бы не взять Kafka. По сути она решает те же задачи, просто находится не внутри, а снаружи нашего сервиса. Так что мы можем предыдущую схему с очередями просто заменить на такую:
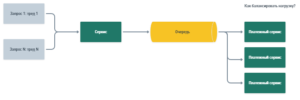
Сообщения из нашего приложения мы просто будем класть в Kafka, а платежный сервис заберет их оттуда сам.
Kafka к сожалению не решит качественно эти проблемы, только количественно. В конце концов, если недоступна очередь, то мы оказываемся в ситуации, похожей на историю с ретраями. Если Kafka недоступна, то сервису остается разводить руками и приостанавливать работу. Именно поэтому для очереди стараются гарантировать очень высокую доступность. И обеспечив высокую доступность Kafka, мы повышаем доступность сервисов, развязав их от прямых запросов друг к другу.
Таким образом, мы приходим к Kafka, когда понимаем, что даже по REST-у все действительно сложно и возникает масса вопросов, которые Kafka помогает решить. Она упрощает взаимодействие со стороны нашего приложения — проще положить в Kafka, чем городить истории с очередями. И она реализует фичи, которые REST дать не может — например, балансировку на стороне клиента.
Также мы получаем нормальный декаплинг. Нам вообще без разницы, доступен сейчас сервис или нет — мы просто закидываем все в Kafka и система становится асинхронной и чуть более стабильной. Мы уходим от антипаттерна хрупкой архитектуры.
Антипаттерн хрупкой архитектуры
Предположим, у нас есть 50 микросервисов, которые синхронно вызывают друг друга по REST. Если выключить один микросервис, цепочка вызовов рано или поздно придет именно к нему и он не сможет обработать запрос прямо сейчас. Можно сказать, что у нас таким образом отваливаются все сервисы разом.
Если мы заменим REST на Kafka, ситуацию мы радикально не улучшим — один из микросервисов все-таки лежит. Но мы точно не ухудшим. Остальные сервисы доступны и по крайней мере могут попытаться ответить из кэша или каким-то иным образом (и хотя бы не создавать паразитного траффика ретраев).
Хрупкая архитектура — это гипотетический пример. Заменять вообще все на Kafka не всегда целесообразно, поскольку очереди усложняют обслуживание. У тебя теряется сообщение, а ты даже не можешь понять, какой микросервис и в какую очередь его недоотправил. И приходится строить распределенный трейсинг, чтобы увидеть, как ходили запросы, разворачивать мониторинг и т.п.
В целом консенсус индустрии мне представляется так: если вы можете не использовать микросервисы, не используйте их. Точно так же и с Kafka. Если вы не знаете, зачем вам нужна Kafka, скорее всего она вам и не нужна. И кажется, не все сейчас понимают, какую именно сложность они приносят, когда вставляют Kafka в проект — скатываются в карго-культ, переходя на Kafka только ради самого инструмента.
Важно оценить сложность своей системы и цену ошибки для бизнеса. Бывают очень простые системы с невысокой ценой ошибки — пришел клиент, вы его не обслужили, потеряли 10 центов. Такие риски можно и проигнорировать. Важно только в какой-то момент не обнаружить себя за написанием еще одной Kafka. Если же цена ошибки — 10 тыс. долларов и иск в суд, дело принимает более серьезный оборот. Тогда имеет смысл защититься от этой ошибки всеми возможными способами, в том числе, через увеличение сложности.
Почему Kafka так популярна
На самом деле брокеров сообщений существует много. Но кажется, что даже с Rabbit все потихоньку переходят на Kafka, потому что это хорошее опенсорсное решение, которое можно гибко настроить под разные сценарии использования. Как будто в определенный момент все просто поверили в концепцию, которая лежит в основе Kafka, и начали ее везде применять.
У Kafka все хорошо с производительностью. Для одного и того же топика можно добавлять партиции и производительность будет расти чуть ли не линейно. Через нее могут ходить миллионы сообщений, вопрос исключительно в том, готовы ли вы платить за сервера.
Как работает Kafka
Для простоты понимания я нарисовал такую схему:
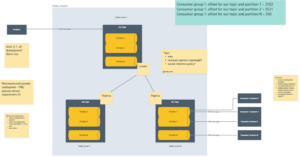
Рабочий процесс как правило начинается с продюсера, который по TCP/IP пишет сообщение в Kafka, делая блокирующий синхронный вызов к кластеру — к одному из серверов, который в данный момент является лидером (в этом смысле ситуация очень похожа на REST).
Внутри Kafka всегда несколько серверов. Один будет Leader — лидером, другие репликами. По факту они дублируют данные друг друга. Работаем (общаемся) мы с лидером, а реплики копируют сообщения с него и готовы подхватить ситуацию, если лидер упадет. Это дает хорошую гарантию доступности.
Как в задаче двух генералов, продюсер ждет от Kafka подтверждения, что сообщение получено. Хотя в коде выглядит так, будто каждое сообщение отправляется мгновенно, на самом деле продюсер отправляет их пачками, складывая в промежуточный буфер. И первая настройка, о которой стоит поговорить, — это способ отправки сообщений:
- Синхронный. Продюсер отправляет сообщение и ждет ответа. При синхронной отправке мы можем гарантировать соблюдение порядка отправки сообщений.
- Асинхронный. Сообщение отправляется, но продюсер не ждет подтверждения доставки и продолжает отправлять последующие сообщения. Так порядок отправки может быть нарушен.
По умолчанию многие используют асинхронную отправку.
Еще одна настройка продюсера — необходимость подтверждения, которая управляет балансом скорости и надежности:
- 0 — Kafka-кластер не должен нам отвечать, получил ли он сообщение. Это самый быстрый вариант.
- 1 — Leader — сервер в кластере, к которому мы обращаемся — должен подтвердить получение.
- All — Leader присылает подтверждение после того, как сообщение получили все реплики. Это необходимо на случай внезапной остановки Leader. Фактически, это 100% гарантия, что сообщение будет получено и не потеряется, но одновременно это и самый медленный способ отправки.
Выбор между способом подтверждения (или его отсутствием) — это очередной trade off.
Для отправки сообщений нужны следующие данные:
- Адреса всех серверов Kafka-кластера, поскольку они прописываются в конфиге. Если одна реплика погаснет, можно подключиться к другой и работать с ней.
- Схема аутентификации в данном Kafka-кластере (логин / пароль, сертификат или что-то еще). Возможно настроить так, чтобы слать в Kafka анонимно, но серьезные ребята обычно делают аутентификацию.
- Имя топика. Часто существуют конвенции по именам топиков. Менять эти имена сложно и больно, поэтому лучше сразу придумать нормальные, чтобы потом не переименовывать.
- Максимальный размер сообщений. Обычно он равен 1 Мб. Его можно увеличивать, но кажется, что с этим лучше не пытаться играться. Для больших сообщений можно взять S3, кидая в Kafka только ссылку на файл. На моем текущем проекте так и происходит — у нас огромный гигабайтные JSON-ы сжимаются при помощи колоночного формата и складываются в S3. В сообщение Kafka при этом добавляется ссылка на эти сжатые файлы.
Внутри сервера есть топик, который разделен на партиции. По сути партиции — это и есть наши очереди. В них сообщения хранятся в виде лога, по которому можно передвигаться вперед-назад — читать последовательно или перескочить на нужное место, чтобы прочитать что-то заново.
Количество партиций настраивается. Можно создать топик с одной партицией, но тогда консьюмеры смогут читать его только в один тред (в один инстанс). Разные сервисы могут читать параллельно из одной партиции, только если они находятся в разных консьюмер группах. А это значит, что несколько инстансов одного и того же сервиса читать из одной партиции точно не могут, т.е. масштабирование будет закрыто. Если же нам нужна балансировка нагрузки на консьюмере, необходимо создавать нужное количество партиций.
У существующего топика количество партиций можно увеличивать очень легко. А вот сокращать это количество скорее всего не получится. Чуть ли не проще бросить один топик и создать другой, если вдруг количество партиций надо уменьшить.
Бывает, что важен порядок прочтения сообщений — они должны читаться строго в том же порядке, в котором отправлялись. В этом случае с помощью правильного ключа их надо отправить в одну партицию. В качестве ключа можно использовать User ID. Все эти тонкости важно понимать на этапе проектирования системы.
Выше я упоминал, что сообщения Kafka пишет в бесконечный лог. В теории мы можем вообще ничего не удалять из этого лога. Но он будет расти и расти, поэтому стоит настраивать политику удаления сообщений, которые уже обработаны. К сожалению, логика Kafka не позволяет “знать”, прочитано сообщение или нет (Kafka сохраняет смещение в логе, но это совершенно не означает, что все предыдущие сообщения были прочитаны, поскольку смещение можно сдвинуть вручную).
Для каждого топика можно задать предельный размер или период времени, сообщения старше которого можно удалять. И эта настройка — предмет боли, потому что сообщение могло быть записано, но не прочитано, даже если прошло довольно много времени. Важно понимать, какие мы устанавливаем ограничения и хватит ли нам их. Допустим, если установить ограничение по объему, но у нас очень интенсивный поток сообщений (миллионы в день), то мы будем слишком быстро выбирать размер топика и все сообщения начнут стираться еще до обработки. Подход тут лучше основывать на бизнес-логике — насколько бизнесу критично, что данные старше определенного времени потеряются? Готов ли бизнес платить за хранение старых сообщений?
А еще в настройке удаления сообщений есть интересный нюанс, связанный с европейскими проектами. У них действует GDPR, из-за которого можно попасть в обратную ситуацию — когда долго хранить сообщения с персональными данными плохо.
По дефолту консьюмеры забирают сообщения из Kafka по TCP/IP не непрерывно, а раз в 5 секунд. Этот период настраивается. По умолчанию сообщения также передаются пачками по 500. Консьюмер также должен регулярно сообщать в Kafka, что он живой. У меня на одном проекте и получение сообщений, и вот этот вот healthcheck осуществлялись в одном треде. И мы так долго обрабатывали полученные сообщения, что не успевали отправить healthcheck — Kafka делала ребалансировку и отключала якобы неработающего консьюмера. И подобных нюансов тут много, в том числе связанных с коммитом смещения в партиции. Рекомендую разобраться.
Предостережения
Если на проекте появилась Kafka, лучше заложить время на то, чтобы подробнее ее поизучать. С Kafka может происходить много разной дичи. Если есть что-то, что может пойти не так, рано или поздно оно обязательно пойдет не так. Поэтому нужно понимать, что вы делаете.
Достоинство и одновременно недостаток Kafka — это ее гибкость. Вы можете настроить очень много пользовательских сценариев. Но важно понимать, что все здесь как в Linux — вам придется это именно настраивать. Ее нельзя просто взять и использовать в своих целях, потому что велика вероятность, что что-то будет работать не так, и поначалу вы даже не будете подозревать об этом. Вы узнаете позже, через боль, ошибки и потери.
Одно дело — настраивать сбор логов через Kafka. В этом кейсе мы собираем очень много данных, которые не боимся потерять. Другой кейс — оплата через Kafka в финтехе. В этом случае сообщения вообще нельзя терять, нельзя снять оплату два раза или вывалиться из определенного тайминга. Это совершенно разные кейсы, в рамках которых к Kafka надо подходить по-разному.
У Kafka много настроек, которые нужно дергать. С ними необходимо ознакомиться. А еще лучше — прочитать пару книжек, потому что условный “Hello world” можно сваять за час. Но если нужно понять, как это работает, придется потратить хотя бы пару недель на начальное обучение.
Статья написана по горячим следам с тренинга по распределенным транзакциям от Дмитрия Литвина.