Один из способов векторизации в задаче распознавания схожих названий товаров при большой нагрузке
Введение в бизнес-задачу
Допустим вы — организация, в которую поступает статистика по покупкам из разных и многочисленных магазинов, не объединенных в одну сеть. У каждого магазина своя база данных товаров. И каждый из магазинов по-своему понимает, какие слова из названия товара характеризуют его наиболее полно.
Кто-то считает, что достаточно назвать товар — «картошка деревенская 1 кг.», а кто-то — «картошка деревенская свежая, молодая 1000 г.», а по факту, это один и тот же товар с одного и того же фермерского хозяйства.
Встает достаточно интересный вопрос — а можно ли идентифицировать все схожие товары, чтоб посмотреть, например, общий поток товара в рамках подопечных магазинов или другие интересные метрики.
И конечно же, идеально идентифицировать это все не выйдет, но определенные шаги в направлении этого объединения сделать можно. О некоторых из этих шагов я расскажу.
Этот проект был выполнен в рамках работ, выполняемых компанией Maxilect, другие проекты этой категории можно посмотреть здесь.
Технические особенности задачи
Особенности проблемы определяются техническими подзадачами, на которые распадается бизнес-проблема:
- Формирование кластеров схожих названий
- Идентификация принадлежности названия кластеру (классификация)
- Организация эффективной обработки большого количества названий
Т.е. сделанное решение должно, с одной стороны — работать технически эффективно, но с другой — тратить очень мало времени на обработку одного названия товара. И в этот момент мы лишаемся большого груза полезных методов, которые хорошо работают на маленьких выборках и большинства стандартных питоновских библиотек для обработки данных.
При нагрузке в 1 млн. товаров в час, в секунду должно обрабатываться как минимум 300 названий товаров, а по факту нагрузка в разные моменты дня может сильно варьироваться, повышая требуемую скорость до 1000 названий/с. Строить векторизации размерности 100 000, использовать word2vec, многоуровневые нейронные сети, модель кластеризации размером в гигабайты… — это все не про нас. Задача сама по себе не вызывает достаточно восторга и не первостепенной важности, чтобы выделять на это горы серверов, которые бы пыхтели, работая с точными, но вычислительно затратными методами.
Таким образом, технический аспект задачи принимает такую формулировку:
Какую бы выбрать экстремально экономичную векторизацию текста, которая бы позволяла относительно эффективно справляться с задачей кластеризации и классификации, пользуясь какими-нибудь совсем простыми методами, чтобы получилось быстро?
После ряда творческих мучений мы пришли к такому варианту.
Векторизация
Вначале (и один раз) составляется «словарь» индексов букв русского, английского алфавита и числительных длины M:
| а | б | в | г | … |
| 1 | 2 | 3 | 4 | … |
Принципиального значения индекс не имеет.
Далее каждое слово в названии товара урезается до N букв (впрочем, это не обязательно). В матрицу V (изначально нулевую) размером MxN добавляются значения в соответствии с такой формулой:
,
где j — номер буквы в слове, W — все слова в названии товара, wj — j-я буква в слове, i — индекс буквы слова в словаре, а f(j,wj,i) — функция весов, зависящая от буквы, номера буквы в слове, индекса буквы в словаре. Логарифм выбран из эмпирических соображений, так как показывал наилучший результат.
Функция весов может быть, например, экспоненциально убывающей при увеличении j. В нашем случае, в качестве функции использовался вектор весов для первых 12 букв, которые подбирались эмпирически. Все индексы в словаре предполагались равнозначными.
Пример:
Пусть у нас есть товар «абв вг», с очевидными индексами [1,2,3] [3,4] и кусочно линейная функция убывания значимости с номером буквы в слове со значениями — f([1,2,3,4,5,6,…]) = [80, 60, 40, 20, 0,0,…].
Тогда матрица V выглядит следующим образом:
| 80 | 0 | 80 | 0 | … |
| 0 | 60 | 0 | 60 | … |
| 0 | 0 | 40 | 0 | … |
| … | … | … | … | … |
В дальнейшем матричная форма используется, чтобы рассчитывать «ключ» данного названия. Ключ названия считается следующим образом:
,
где V1 — первая строка матрицы V, а Idx(V1>0) — функция, которая находит индексы всех ненулевых первых букв.
В некоторых аспектах эта векторизация вдохновлена сходством Джаро-Винклера. А именно, с наличием префикса у слова и большей значимостью первых букв.
Кластеризация
В качестве кластеризации тут описан достаточно простой и банальный алгоритм обучения без учителя. Однако, ничего не мешает использовать что-то более изощренное. Данный используется только по причине скорости и простоты. Его особенностью является то, что он должен породить крайне много маленьких кластеров и количество этих кластеров заранее неизвестно.
На входе алгоритма V — неклассифицированная векторизация названия товара, K — ключ для этой векторизации, Model — словарь, модель кластеризации.
Собственно алгоритм:
1. Model = dict()
2. Для всех векторизированных названий товаров V с ключом K
a. Если K не в Model.keys:
i. Создаем новый кластер C с центром V
ii. К новому списку из Model[K] добавить C
b. Иначе:
i. Для каждого кластера из Model[K]:
1. Выбираем наиболее близкий кластер к V
2. Если все кластеры слишком далеко создаем новый и добавляем в Model[K]
3. Если есть близкий, пересчитываем центр кластера, добавляя в него новый элемент V
3. Return Model
Матрицы векторизации при «обучении» «разравниваются» в вектор, потому что их матричные свойства нужны только на этапе расчета ключа (да и там не очень сильно). Близость рассчитывается по косинусной мере (было проверено несколько, и эта дала лучший результат). Существует ограничение, что если вектор дальше от центра по мере, чем некоторое число, считается, что это другой кластер.
Осознанной проблемой данной реализации может стать то, что при смещении центра кластера какие-то из элементов соседних кластеров могут стать ближе к этому кластеру, чем к другим. Однако итерационная процедура нахождения равновесия может «съесть» много соседних элементов и объединить много лишнего в единый кластер.
Альтернативой является простое «не пересчитывание» центра. Пункт (1.b.i.3) просто игнорируется. В целом, хуже становится не настолько, чтобы сильно об этом сожалеть.
Классификация
Обучение — это вещь, достаточно изолированная от «процесса» в организации, можно поставить сервера обучаться недельку, а потом внедрять модель. И так раз в месяц. А вот классифицировать по модели надо быстро, обрабатывая кучу информации за малое время.
В данном случае основная пляска с бубном происходит вокруг ключей, которые не совпадают с ключом входящего названия, но могут быть похожи.
На входе алгоритма V — неклассифицированная векторизация названия товара, K — ключ для этой векторизации (тут важно, что это множество), Model — модель кластеризации, Applicants — список ключей претендентов на то, что в соответствующих списках из словаря есть нужный кластер, СSd — ограничивающая константа, Sym_diff() — функция симметрической разности.
Алгоритм выглядит таким образом:
1. Applicants = []
2. Если K находится в Model.keys:
a. В Applicants добавляется K
3. Иначе:
a. Для каждого MK из Model.keys:
i. Sd = Sym_diff(MK,K)
ii. Если len(Sd) < СSd:
1. В Applicants добавляется MK
4. Для каждого кластера из каждого списка с ключами из Applicants:
a. Выбираем наиболее близкий кластер к V
b. Если все кластеры слишком далеко, мы ничего не нашли, возвращаем пустой элемент
c. Если есть близкие, возвращаем самый близкий из них
В алгоритме проверки схожести кластеров также есть ограничение по косинусной мере, которое говорит нам, что этому кластеру точно название не принадлежит.
Тестирование
Наиболее выразительный тест – это тест, придуманный не нами.
В один прекрасный момент глубокой удовлетворенности результатами работы более ранней версии алгоритма, когда на исходных данных задания показывались только двузначные чиселки с цифрой 9 на нужном месте, пришел вариант схожего задания с тестовой выборкой. И тут, внезапно, процент точности распознавания упал где-то до 60. Это, впрочем, было тоже неплохо, потому что у людей, которые эту выборку выдали правильных распознаваний было в районе 40%. Но тем не менее, происходящее вызвало столь же глубокое чувство толка противоположного изначальному и желание переосмыслить происходящее. Результатом этого переосмысления и является вышеизложенный алгоритм и результаты тестирования показываются на нем.
Двумя основными параметрами, которые можно варьировать при классификации являются:
- Ограничение расстояния по мере, которое говорит нам, что это точно не тот кластер distance range
- Ограничение сверху на включение список кластеров в «претенденты» cut length
Естественно, с увеличением cut length может достаточно сильно увеличиться количество рассматриваемых кластеров «претендентов», что не слишком хорошо сказывается на скорости классификации. Однако, при этом уменьшается количество кластеров, которые просто были выкинуты из рассмотрения, потому что их ключи нигде не нашлись.
Мы провели измерение различных показателей эффективности алгоритма для таблицы 20×20 управляемых параметров, чтобы посмотреть, что выйдет:
- Тестовая выборка содержит 923 сочетаний названий товаров и «правильных» названий товаров
- Модель обучалась по всем уникальным названиям товаров из «правильных»
- Если найденный товар не нашелся в модели, на выходе пустое множество. Если нашелся, но неправильно, то на выходе False. Если правильно — True
- Далее все эти данные агрегируются в количество классифицированных, количество правильно и неправильно классифицированных
Вот что вышло с процентом товаров для которых нашлась классификация:
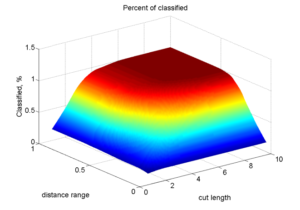
Уменьшение distance range до значений меньше 0.5 и cut length до значений меньше 4 ведет к резкому уменьшению количества распознанных товаров. Если оба параметра превышают эти значения, алгоритм выходит на плато со 100% распознаванием (что, впрочем, не всегда теоретически может быть хорошо).
Это достаточно очевидная зависимость, потому что оба этих параметра способствуют отсечке или не найденных соответствий ключей, или товаров, которые ни к кому не близки по мере.
С эффективностью распознавания все несколько более интересно, потому что зависимость количества некорректно распознанных товаров от этих двух параметров выглядит достаточно необычно:
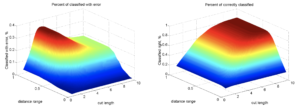
Максимум на cut length от 2 до 4 соответствует резкому наращиванию количества списков кластеров «кандидатов». В ситуации достаточно большого размаха distance range, в этих списках кандидатов находится много лишнего. При этом, при увеличении количества «кандидатов», вероятность найти «реально» минимального по мере растет, поэтому ошибка начинает спадать до умеренных 17% с 34%.
И наконец, самое важное — процент правильно распознанных. Сначала может показаться удивительным, что в этом графике нет максимума. Но потом мы вспомним, что процент неправильно распознанных считается относительно собственно всех распознанных, количество которых монотонно повышается при увеличении значений обоих параметров. А процент корректно распознанных — относительно всей выборки.
Мини-вывод
В конечном итоге мы добились, чтобы на внешнем наборе данных мы получили хоть сколько-то приемлемый, но быстрый результат. 83% правильных распознаваний. Для задачи с достаточно большой вариацией одного типа формулировки это неплохо. Миллион наименований товаров классифицируется на одном скромном IP, G4520, 3.6GHz с 8 гигабайтами памяти в течение 1-2 минут. Можно было лучше распознавать и кластеризовать? Естественно. Всегда есть куда стремиться.
Приложение. Вопросы, проблемы векторизации и исправляющие эвристики
Стеммер при обрезании слов?
Стеммер имеет привычку удалять префиксы, а это нам не надо. В одинаковых названиях товаров чаще всего сохраняются первые части слов, хотя могут «коверкаться» концы:
- Картошка молодая
- Картофель молодой
- Карт. Молод.
- Крт. Мол.
- …
Никаких «накартошек» и «покартошек» нет. А если и есть, скорее всего это не имеет отношения к просто картошке.
А как же использовать контекст слова, как это нынче модно?
Проблема в том, что в названиях товаров чаще всего контекст гораздо более расплывчат, чем в осмысленных текстах. Например, вполне нормальное название товара — «коровка золотая космическая», маркетинг использует существительные и прилагательные максимально извращенным способом, чтобы обозначить некоторую уникальность товаров. И в этом вопросе осмысленность словесных сочетаний не имеет особого значения, поэтому «выделение» контекста дает не больше, чем простой пересчет похожих слов в названиях товара.
Слова с двумя или более корнями? Если обрезать слова, они становятся неразличимыми.
К некоторой удаче, специфика задачи такова, что люди не любят товары, которые называются слишком длинными словами, поэтому «Besserachtseitelesendannfunfminutenvideoseenaitung» никто продавать не будет (да и не сможет, потому что это свойство человека). Однако, в общем случае, это, безусловно, некоторая головная боль, которая для лечения требует разбивать слова по корням.
Числительные?
а) Одна из проблем с числительными, это то, что собственно только ими товары и отличаются. Например:
ATI Radeon 570, HDMI™ 2.0, DisplayPort 1.4 HBR3/HDR Ready
ATI Radeon 560, HDMI™ 2.0, DisplayPort 1.4 HBR3/HDR Ready
Слова все одинаковые, числа отличаются только во второй цифре, а товары разные! В случае обработки информации об IT товарах есть смысл придавать числам большие веса в функции f(), чем словам, потому что многие товары отличаются только версией, при этом обладают одинаковыми описаниями. Таким образом, требуется еще одна предварительная классификация товара, как товара из IT или технической области.
Еще одним решением такой проблемы будет предварительное превращение всех числительных в названии в слова.
б) Еще одна важная проблема — это единицы измерений. Например:
Шампунь, ежик пушистый, 1000 мл.
Шампунь, ежик пушистый, 1 литр.
Числительные разные, а товар один. Естественно, тут решение одно — иметь словарь преобразований единиц и все числительные, снабженные нужными подписями, преобразовывать к единым единицам измерения. Это затормозит процесс, но не сильно.
Специфика подбора ключей кластеров
Ключи должны разбивать все «пространство» элементов кластеров максимально равномерно, чтобы избежать перегруженности списков с элементами кластеров внутри словаря ключей. Иначе перебор внутри списка займет много времени. Требуется выдерживать некоторое равновесие между количеством ключей и размером списков внутри словаря.
А что, если ключ нашелся в одном списке, а товар, на самом деле, лежит в другом?
Чаще всего это означает то, что товар назван так, что уже почти ничего схожего с «оригиналом» у него не осталось. Однако, проблема может быть решена включением ближайших ключей в список «подозрительных». Подобное может затормозить процесс, но положительно сказаться на точности классификации. За счет этого можно отыграть где-то 3-4%.
Автор статьи: Александр Беспалов, Специалист по анализу данных, Maxilect