Самая суть цепочек рекламных каналов вызывает непреодолимое желание узнать, что вероятнее всего произойдет дальше в цепочке. Будет конверсия или нет?
Но это похвальное стремление часто утыкается в проблему. Если пытаться удерживать количество ложно-положительных результатов в разумных рамках, количество истинно-положительных не впечатляет. Как следствие — результаты анализа зачастую не позволяют нам принимать адекватные управленческие решения. Адекватное прогнозирование требует больше данных, чем просто короткие цепочки пользовательских прикосновений к каналам. Но это вовсе не значит, что задачу стоит бросать.

В этой статье мы расскажем вам немного о серии экспериментов по разработке алгоритма прогнозирования конверсии. Эта статья — продолжение двух предыдущих на схожую тематику. Вот первая, Вот вторая.
Постановка задачи
Любой, кто имел дело с машинным обучением в контексте прогнозирования, знаком с LSTM (RNN нейронными сетями). Но у нас «прогнозирование» сводится к еще более простой задаче. Спрогнозировать конверсию — это значит классифицировать ту или иную цепочку, как принадлежащую классу «сконвертировавшихся в будущем».
Для LSTM существует огромное количество отличных материалов по созданию системы, которая предсказывает значения временных рядов и буквы в словах. В нашем случае задача была еще проще, на первый взгляд.
- Анализируя взаимодействие каналов, мы можем составить то, что выглядит как алфавит, где буквы — это отдельные каналы. Например — «(канал) 1», «(канал) 2»,…
- Из букв получается огромное количество «слов» в виде цепочек, которые являются всевозможными комбинациями взаимодействий между пользователем и каналами. Например, цепочка = «1», «2», «1», «3»; цепочка = «2», «4», «4», «1»;…
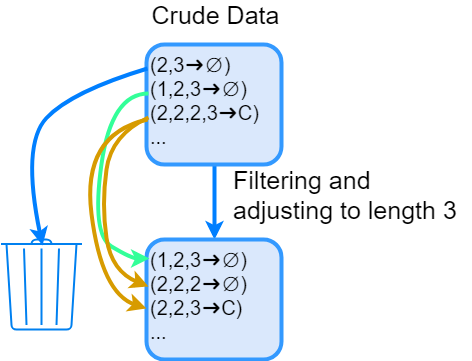
Рис.1. Обработка грубых данных для удаления слишком коротких и расщепления слишком длинных цепочек.
Наша цель — определить комбинацию касаний, которая максимизирует вероятность конверсии по всей базе потребителей для цепочек выбранной длины. Для этого мы выделяем слова (цепочки) требуемой длины из всей выборки. Если цепочка длиннее заданной, она расщепляется на несколько цепочек желаемой длины. Например — (1,2,3,4) -> (1,2,3), (2,3,4). Процесс обработки изображен на рисунке 1.
Первая попытка найти простое решение
В этой попытке мы обучили сеть LSTM «почти сырым» цепочками одной длинны и получили значение RUC AUC где-то около 0.5, что говорит нам, что точность классификатора стремится к эффективности подброса монетки. Упс. Не сработало. Но попытаться сделать в тупую же стоило? Вдруг бы прокатило. Но нет. Пришлось немного подумать.
Анализ происходящего
Ключевое наблюдение 1
Однородные цепочки в этом исследовании бесполезны. У них конверсия зависит только от длины цепочки и номера канала, классификатор для них строится логистической мультирегрессией с двумя факторами. Категориальный фактор — номер канала, и числовой — длина цепочки. Получается довольно прозрачно, хотя и бесполезно, потому что достаточно длинные цепочки в любом случае подозрительны на конверсию. Поэтому их можно не рассматривать вообще. Тут, надо отметить, что размер выборки существенно сокращается, потому что обычно где-то 80% всех цепочек однородные.
Ключевое наблюдение 2
Можете выбросить все (принципиально) неактивные каналы, чтобы ограничить объем данных.
Ключевое наблюдение 3
Для любой цепочки вы можете применить one-hot кодирование. Это устраняет проблему, которая может возникнуть, если маркировать каналы как числовую последовательность. Например, выражение 3 — 1 = 2 не имеет смысла, если числа это номера каналов (Рис.2.).
Кроме всего прочего, мы попытались закодировать цепочку еще некоторым количеством странных способов, которые строились на различных предположениях о природе цепочек. Но так как это нам ничем не помогло, мы об этом говорить не будем.
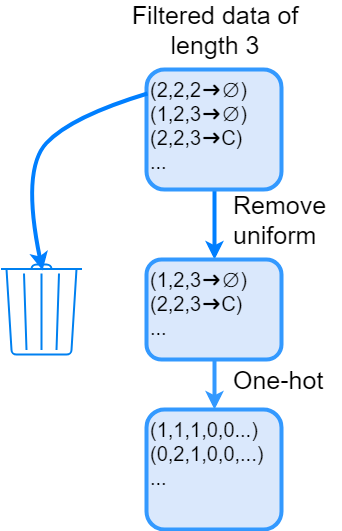
Рис.2. Второе преобразование данных. Удалите все однородные цепи, примените one-hot кодирование.
Вторая попытка простого решения
Для разных вариантов кодировки цепочек были испробованы такие инструменты для классификации:
- LSTM
- Multiple LSTM
- Многослойный персептрон (2,3,4, слоя)
- Random Forest
- Gradient Boosting Classifier (GBC)
- SVM
- Deep Convolutional Network (c 2 слоями, чисто на всякий случай)
Параметры всех моделей оптимизировались с помощью алгоритма Basin-hopping. Результат оптимизма не вызывал. AUC ROC поднялся до 0.6, но в нашем случае этого было явно недостаточно.
Третья попытка: простое решение
Все происходящее естественным образом привело к мысли, что наиболее важно разнообразие состава каналов цепочек и фактический состав каналов при условии цепочек одинаковой длины. Это не настолько банальная мысль, потому что обычно считается, что еще важен порядок. Но предыдущие эксперименты с LSTM показали, что даже если это и так, это сильно нам не поможет. Поэтому надо максимально сфокусироваться на составе цепочки.
Например, можно удалить все дубли из цепочки и отсортировать, полученный список. Это можно сделать примерно таким простым кодом на питоне:
sorted_chain = tuple(sorted(list(set(chain))))
Преобразование к tuple нужно, чтобы потом использовать эту цепочку как ключ в словаре паттернов. После этого можно сосчитать, сколько и каких цепочек получилось. Получается, как на рисунке 3.
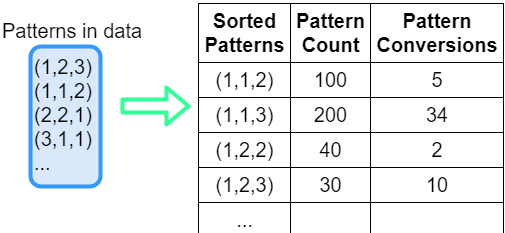
Рис.3. Сортировка и подсчет шаблонов цепочек
На первом проходе мы можем рассчитать средний коэффициент конверсии для каждой цепочки «шаблона» в данных.
Теперь мы сортируем получившийся список по убыванию конверсии и получаем классификатор с параметром «отсечки по конверсии». Проверяя тестовую цепочку, преобразованную вышеуказанным методом, на наличие одного из паттернов из списка с конверсией больше заданной, мы классифицируем ее как ту, которая породит конверсию, или бесполезную. Теперь мы можем протестировать все входящие цепочки с помощью этого классификатора уровня конверсии и предсказать результат. На основе того, что вышло, мы построили единственный график в этой статье, который показывает преимущество такого подхода. ROC кривую для этого подхода, который тут назван — Pattern Check.

Рис.4. ROC кривые для разных классификаторов.
Для нашего нового метода AUC = 0.7. Это уже что-то. Не прям победа, но уже далеко не подброс монетки. Замечание. Этот метод можно реализовать и без использования one-hot, как тут и описано для понятности, но при желании развить успех, он уже может потребоваться.
Выводы
При слове «паттерн» у людей, знакомых с машинным обучением сразу возникает мысль — «сверточные нейронные сети!» Да. Это так, но мы про это сейчас писать не будем. Мы привели тут неплохой, как нам кажется, метод преобразования цепочек, который с ходу дает возможность получить классификатор(предиктор), который работает лучше, чем использование в лоб даже самых продвинутых технологий. Его уже можно использовать для выделения группы пользователей с большой вероятностью конверсии и не бояться тысяч ложно-положительных. Для наших данных, при выборе отсечки в алгоритме по конверсии 0.25, мы получили для 5112 конверсий тестовой выборки, 523 истинно положительных и 1123 ложно-положительных, что в принципе, терпимо, при условии, что в тесте было 67 тыс. человек.
Автор статьи: Александр Беспалов, Data scientist, Maxilect.