Предисловие
Эта поучительная история о том, что, чтобы получить какое-то новое знание о процессе, обычно недостаточно просто найти какой-то новый метод, применить его к имеющейся постановке задачи и интерпретировать результаты привычным образом. Требуется некоторый внутренний прогресс подхода к проблеме.
Стояла задача применения Марковской модели для атрибуции каналов трафика, потому что Google Analytics такого не позволял. Особенностью было добавление в атрибуцию рекламных каналов купонов, изолированных от гугл-аналитики. Эта, вроде как не очень значительная особенность, и определила ход решения задачи, результаты и практическую применимость этих результатов. Об этом и рассказ.
Этот проект был выполнен в рамках работ, выполняемых компанией Maxilect.
Контекст
Безусловно, изначально стоит пояснить о чем тут речь и что вообще такое «атрибуция каналов». Реклама это двигатель торговли, поэтому если какая-нибудь организация хочет что-то продавать в интернете, она исследует вопрос, на какие именно рекламные объявления люди больше всего реагируют, и где именно. Каждое место, где можно кликнуть на рекламу – это канал трафика. И человек перед покупкой может пройти по нескольким таким каналам (по цепочке каналов), прежде чем что-то купит.
Встает фундаментальный вопрос – а какой именно канал был главным в принятии покупателем решения что-то купить? Какой именно из всех каналов в цепочке атрибутировать к покупке? А может это не один а несколько каналов ответственны за покупку? Это вопросы, на которые так или иначе отвечают рекламные аналитики. Или пытаются отвечать.
Проблема атрибуции каналов трафика
Google Analytics позволяет в решении этого вопроса достаточно разгуляться фантазии. Предлагается большой выбор моделей атрибуции, «распределяющих» покупку по каналам:
- В самом простом случае можно считать, что последний канал и вызвал покупку.
- А еще можно считать, что ответственность каналов падает линейно или экспоненциально со временем.
- Можно предположить, что 40% ответственности на первой рекламе, 40% на последней, а все остальные промежуточные каналы – 20%.
Это все называется умными словами, типа – «Last click model», «Time decay model», «40-20-40 model». Много моделей существует. А ведь еще у каждой модели есть параметры разные, которые можно настраивать и в зависимости от них получать разные результаты!
Уже само количество моделей ясно говорит, что то, как оно на самом деле, никто не знает. Дается куча разных инструментов, а дальше если вам вдруг показалось, что оно именно так и происходит, как предсказывает модель, значит можете смело так и считать. Никто не заметит разницы.
Этот разгул субъективизма создает непреодолимое желание опираться не на собственный произвол в выборе модели и ее параметров, а на сколь бы то ни было объективную реальность. Тут и появляется модель Маркова, которая опирается на факты. Ее-то нас и попросили реализовать для данных компании myToys, параллельно попросив реализовать дополнительную интеграцию в атрибуцию каналов купонов.
Модель Маркова как решение
В модели Маркова, в качестве меры вклада конкретного канала в покупку, выступает вероятность совершения покупки при условии «касания» этого канала и за некоторое количество шагов. Количество шагов тут достаточно чувствительный параметр, потому что при увеличении количества шагов вероятность «купить» стремится к 1. То есть если ты 100 раз кликнул рекламу велосипеда, наверное, стоит предположить, что ты хочешь именно велосипед и его купишь.
К счастью, цепочки даже с 10 каналами это уже доли процентов. Поэтому можно откинуть одношаговые цепочки, потому что в них Last Click безальтернативен. Далее усреднить распределения, получаемые для длин цепочек от 2 до 10, с весами, определяемыми долей цепочек такой длины в общем количестве цепочек. И наконец отнормировать на 1. Но это не обязательно, потому что при атрибуции так или иначе сумма весов нормируется на 1, ведь в конкретные цепочки могут попадать далеко не все каналы из распределения, но в сумме должна получаться всегда одна полная покупка. Такой подход эмпирически показал себя наиболее адекватным.
Но кроме модели Маркова требовалось еще реализовать встраивание атрибуции каналов купонов.
Проблема атрибуции каналов купонов
В школе, на уроках физики всех нас сурово порицали за попытки складывать овец с утюгами. Этот травмирующий детский опыт недвусмысленно подсказал, что каналы купонов и каналы трафика это вещи достаточно разные. Одно дело, когда ты тыкаешь в какую-нибудь картинку в поисковике или соцсети серфя по интернету. Другое дело, когда тебе на улице дают бумажку, или покупка в каком-то одном магазине дает тебе скидку во втором, или ты в программе лояльности, и тебе в рассылке что-то предлагают.
Можно взять купон на улице, потом случайно наткнуться на рекламу в интернете, нажать, вспомнить, что есть код со скидкой по купону и купить. Что тут повлияло на покупку – купон или реклама? А что если взять купон, а потом купить только после третьего канала трафика? Что подействовало?
Мы не можем реконструировать по времени, когда именно купон «подействовал». Временное положение купона в цепочке не определено. Таким образом, все модели, которые используют отсортированную по времени последовательность касаний каналов трафика, априори неадекватны ситуации с купонами. А проще говоря — вообще все, кроме цепей Маркова.
Но, по факту, у цепей Маркова тоже ситуация не лучше. Система регистрации узнает о купоне только во время покупки. Поэтому в любой нашей статистике переход от купона к покупке всегда происходит с вероятностью 100%, а переходов от каналов трафика к купонам и вовсе не происходит. Естественно, считать, что за покупку ответственен только купон и больше ничего, достаточно неадекватно.
Решение проблемы атрибуции каналов купонов
Если какие-то вещи не хотят друг с другом адекватно взаимодействовать, проще всего их разделить, чтобы они друг другу не мешали. Было сделано так, что каждый купон начал «создавать» отдельный «столбец» атрибуции каналов трафика. Проще всего это изобразить в таблице атрибуции покупок (модель атрибуции тут не принципиальна):
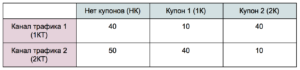
В отсутствии купонов было сделано 90 покупок (первый столбец). 40 из них было атрибутировано 1КТ, 50 — 2КТ. С использованием 1К было 50 покупок, 40 из которых атрибутированы 2КТ (второй столбец). И т.д.
Также можно схлопнуть таблицу до «безкупонной» атрибуции, сложив все элементы строк. Таким образом 1КТ атрибутировано 90 покупок, а 2КТ — 100.
Данная таблица, в том числе, иллюстрирует дополнительную аналитическую силу такого подхода, показывая, что 1-ый купон лучше работает со вторым каналом трафика, а 2-ой купон — с первым.
Результат и рефлексия
В результате был реализован и отлажен интерфейс, который позволял формировать отчеты атрибуции каналов трафика по нужным срезам купонов и скачивать их в формате xls. Марковская модель и несколько стандартных моделей были реализованы. Пользователь имеет возможность настройки нужной ему модели атрибуции, среза по купонам, временного отрезка для отчета и агрегации результатов.
Технически, результат проекта был сугубо положительный, а изящное решение проблемы атрибуции купонов давало все поводы для гордости от хорошо сделанной работы. Однако.
На практике атрибуция моделью Маркова дала результат крайне похожий на результат с использованием Time Decay. Из этого можно предположить, что наиболее используемые каналы имеют тенденцию появляться последними в цепочке (что достаточно логично, особенно задним числом). Таким образом, использование именно этой модели практический результат дало спорный, сколько бы не приближало нас к некой объективности, которая, впрочем, с реальными причинам покупок не сильно связана.
«Двумерная» атрибуция, предложенная выше для решения проблемы атрибуции каналов купонов, настолько сильно отличалась в использовании от типичного подхода для анализа трафика, что не была принята на вооружение в полной мере. Сколь много потенциальных возможностей не открывал бы такой подход, он требует применения уже более изощренных статистических методов анализа и навыка видения ситуации сразу в двух измерениях.
Автор статьи: Александр Беспалов, Специалист по анализу данных, Maxilect