На недавней ИТ-посиделке мы обсуждали боль и страдания, связанные с обратной совместимостью систем. С одной стороны, ее поддержка значительно усложняет проект — правки, касающиеся взаимодействия каких-либо компонент, становятся многоэтапными. С другой стороны, только так можно обеспечить бесперебойную работу сервисов.
В этой статье мы хотим рассказать об обратной совместимости тем, кто еще с ней не сталкивался с точки зрения архитектуры. Далеко углубляться не будем — введем базовые понятия, поговорим о плюсах и минусах.

Статья подготовлена по результатам выступления Андрея Бурова (Максилект) на внутреннем митапе.
По определению обратная совместимость — это способность программного обеспечения работать со старыми версиями системы. Все мы, как пользователи, сталкивались с тем, когда обратная совместимость не работает — накатываешь обновление Android, а какой-то софт прекращает работать.
Свой рассказ начну с самого простого примера — как не наступить на грабли при обновлении, чтобы пользователи не сталкивались с неработоспособностью системы.
Предположим, у нас есть классическая архитектура: база данных, бэкенд, который с ней работает, и фронтенд. Пусть фронтенд работает с бэкендом, используя некое API v1. И предположим, что в новом релизе должны быть добавлены некоторые фичи, из-за которых API пришлось сильно поменять — он станет API v2 (предположим также, что API v1 сильно отличается от API v2).
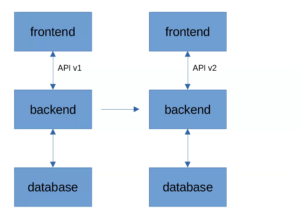
Согласно классическому заблуждению, нам достаточно одновременно обновить бэкенд и фронтенд, чтобы не думать про обратную совместимость вообще. Казалось бы, фронт работает по API v2, бэк — тоже, зачем усложнять?
Но не все так просто.
Начнем вопроса, а что означает одновременное обновление?
Фронт и бэк вполне могут деплоиться отдельно. Часто бывает, что разрабатываются они разными командами, да еще и движутся к проду различными путями (например, что-то в Docker, что-то в nginx). И в любом случае, даже если процесс обновления запустили одновременно, кто-то из них закончит первым. Между обновлением первого и второго будет некий интервал времени, в течение которого API фронта и бэка будет несовместимым, а пользователи увидят ошибки при попытке выполнить какие-либо действия с сервисом.
А еще “достанется” пользователям, у которых есть своя копия фронта в браузере. Допустим, это SPA, который взаимодействует с бэком по REST API. Пользователь загрузил страницу и спокойно с ней работает, например заполняет форму. Обновив сервис на серверах, мы лишаем пользователя возможности засабмитить введенные данные — старый фронт отправит на бэк запрос по API v1 и все упадет с ошибкой. Пользователю придется перезагрузить страницу и заполнять данные заново.
Чтобы такого не произошло, можно обновлять бэкенд за два шага.
Делим обновление на две части
Избежать описанной выше ситуации поможет промежуточный релиз бэкенда, поддерживающий сразу обе версии API — v1 и v2. Когда мы накатываем эту версию, фронт продолжает работать как раньше, поддерживая API v1. На следующем этапе мы обновляем фронт — переходим на API v2 и не получаем никаких специфических эффектов.
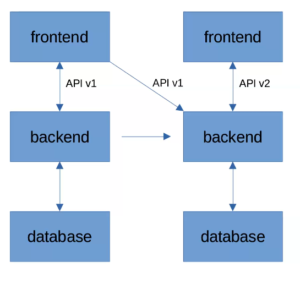
У такой схемы есть дополнительный плюс. Если по каким-то причинам бэкенд мы накатили, а обновление фронта задерживается (нашли критическую ошибку, сгорела рабочая станция с исходниками… да по любой причине), нам не потребуется ничего откатывать. Новую версию фронта можно выкатить и на следующей неделе — пользователи от этого не пострадают.
После успешного обновления фронта можно в одной из следующих версий бэкенда убрать поддержку старого API.
Этот рассказ опирается на пример обращения фронта на бэкенд, но ситуацию можно спроецировать на любое взаимодействие систем. Те же идеи можно использовать при обновлении API взаимодействия двух самостоятельных сервисов. Удобно, если один из сервисов будет часть времени поддерживать обе версии API (в этом случае он не сломает тех, кто его вызывает).
Но вернемся к вопросу обновлений. Мы сократили downtime из-за неодновременного обновления бэкенда и фронтенда, но полностью от него не избавились. Когда мы накатываем новую версию бэкенда, он в течение какого-то периода времени не принимает запросы. Это время может быть большим или маленьким, но в любом случае оно не нулевое. А еще чисто теоретически даже протестированная новая версия может вообще не подняться. Как быть в ситуации, когда такого простоя мы допустить не можем?
Теперь на две части разделим бэкенд
Чтобы сократить downtime, остается поднять второй бэкенд и обновлять поэтапно. Сначала потушить и обновить backend 1, а когда он нормально заработает, то же самое проделать с backend 2.
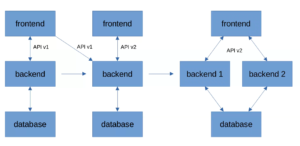
Если речь не про API, а про базу данных
Усложним условие задачи.
Предположим, нам нужно не обновить API взаимодействия, а переименовать колонку в базе данных. Допустим, в названии колонки была опечатка, которую нужно поправить.
Как это сделает “сферический разработчик в вакууме”?
Он добавит ренейм колонки в свое обновление бэкенда. Выполнит миграцию backend 1, тем самым переименует колонку и “уронит” backend 2, который в это время должен обрабатывать пользовательские запросы (backend 2 ничего не знает о переименовании и все еще работает со старым названием колонки). Пользователи будут получать ошибку, пока мы не обновим backend 2. А произойти это может не сразу, как и в предыдущих примерах.
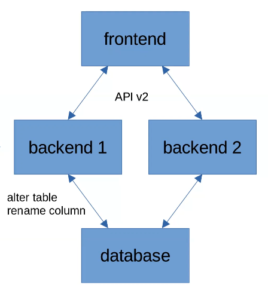
Здесь логично применить ту же логику разделения обновления на два этапа. На первом этапе мы должны добавить в базу новую колонку с правильным названием, чтобы она работала параллельно со старой. И только в следующем релизе можно будет удалить старую колонку.
Аналогично вносятся и другие изменения, например смена типа данных.
Добавляем новые фичи так, чтобы ничего не сломать
Легко добавлять новые фичи в системы, которые выглядят как на картинке:

Это система, которая вам нравится и хорошо знакома. Вы работаете над ней не один год, знаете все ее закоулки и подводные камни, догадываетесь, что и где нужно дописать. Если нужно добавить новую фичу, проблем не возникает — вы просто ее дописываете, на этом история заканчивается.
Но таких идеальных ситуаций не бывает почти никогда, разве что на пет-проектах или совсем свежих разработках, которые еще не дошли до прода. Если же над проектом уже несколько лет трудится с десяток и более разработчиков, для нового человека, который только пришел и не успел во всем разобраться, внешне он будет выглядеть как-то так (даже если на самом деле архитектура продумана, а код написан грамотно):

По-хорошему, перед добавлением новой фичи, надо все это перебрать, разложить у себя в голове по полочкам и только потом планировать, что и куда писать. Но изучить большой проект целиком, если ты не стоял у его истоков, крайне сложно. В разумные сроки этого не сделать (и этого уж точно не успеть, если на реализацию фичи у вас 1-2 дня). Поэтому в большинстве случаев, когда разработчику, нанятому на существующий проект, предлагают реализовать какой-то новый функционал, он пристраивает его сбоку, чтобы лишний раз ничего не поломать. Фактически, он реализует ее отдельно, присоединяя к проекту какой-то “ниточкой”.

Почему фича должна быть отключаемой
С точки зрения стабильности такого проекта лучше, если по умолчанию новый функционал отключен. Включаться он должен через некоторый задокументированный рычаг (фича-флаг).
Так в командах делают довольно часто. Фичи вносят в код, они попадают в релиз, но кто и когда их включит на продакшене, изначально неизвестно. Произойти это может и через месяц, и через два. Это логично, поскольку в релизе могут быть гораздо более критичные вещи, например исправление важных ошибок. Если он будет падать из-за подключения второстепенного функционала, это неправильно, поскольку:
Стабильно работающий на проде сервис — гораздо более ценен сам по себе, чем любая даже самая классная новая фича.
Именно поэтому при добавлении нового функционала основной упор делается на то, чтобы не поломать уже существующее.
Фича-флаги — в целом полезный инструмент. Среди прочего их можно использовать для тестирования нового функционала. Можно настроить права доступа таким образом, чтобы новый функционал могли для себя включить только некоторые пользователи. Когда они удостоверятся, что функционал работает корректно, фичу можно включать для всех.
Однако когда в проекте очень много отключаемого функционала, в нем можно запутаться, особенно если разработчики этих фичей не позаботились о нормальной документации. С порога не всегда понятно, какие фича-флаги надо включить, чтобы поднять систему. Да и при изучении чужого кода не всегда ясно, он участвует сейчас в работе или отключен очередным флагом, потому что где-то что-то не сработало? А ведь есть еще и устаревшие фичи, которые просто отключили флагом, но по каким-то причинам не выпиливают из кода.
Весь этот код усложняет понимание проекта новым человеком, а значит только усугубляет описанную выше ситуацию с добавлением нового функционала.
Фича-флаги — элемент, за которым стоит следить отдельно. После того как функционал выкатили в продакшн и приняли решение его уже не удалять, соответствующий фича-флаг стоит выпилить из проекта, а не оставлять мертвым грузом в коде. Когда функционал устарел, его также стоит удалить целиком, а не отключить временной мерой.
Подводим итоги
Вопрос обратной совместимости связан не только с кодом, но и с инфраструктурой проекта на продакшене. Иными словами, разработчик, который пишет код для прода, должен хорошо представлять, как все это работает, иначе он не сможет правильно поддерживать обратную совместимость при обновлениях. В описанных примерах обновления API и исправлений в БД была важна коммуникация между бэкенд-разработчиками и девопсами. Если она нарушена, разработчики в принципе не имеют возможности написать корректный код.
Обратная совместимость поддерживается не всегда. Иногда затраты на ее реализацию много больше потерь из-за того, что некоторое количество пользователей столкнутся с ошибками во время обновления. Поэтому на самом деле ответ о целесообразности обратной совместимости стоит ждать от бизнеса. И зависеть он будет не только от глобальных взглядов на клиентов и ценность продукта для них, но и от банальных вещей, вроде скорости обновления. Также будут играть роль масштабы проекта. Чем он больше, тем обратная совместимость важнее. В предельном случае какого-нибудь “кровавого энтерпрайза” заранее неизвестно, что еще может поломать изменение API или схемы данных — тут речь пойдет уже не только о комфорте пользователей, но и о работоспособности системы в целом.
В критичных, например финансовых система, вопрос обратной совместимости однозначен — она необходима. Нормальная ситуация, когда для любого изменения в базе нужно четыре и более релизов (например, создать новую колонку, начать из нее читать, перестать читать из старой и удалить старую колонку). А для какого-нибудь стартапа это просто неподъемный объем работы — компания не сможет быстро выйти на рынок, если под каждое изменение будет требоваться столько преобразований.
Аналогична ситуация с рычагами управления новыми фичами. Это всегда усложнение и так непростого проекта. Но на противоположной чаше весов стабильность всей системы. Готов ли заказчик столько платить за стабильность — вопрос индивидуальный и зависит от особенностей проекта. Чем проект крупнее и критичнее, тем, как правило, этой готовности больше. В крупных финансовых проектах вполне нормальна ситуация, когда внутри команды даже выступают с докладами о том, что за фича-флаги присутствуют в коде и как с ними обращаться. А стартапу скорее всего это просто не нужно.